 宅哥聊构架 2022
2022-10-21
宅哥聊构架 2022
2022-10-21

持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第4天,点击查看活动详情
写代码之前先回顾一下RNN的计算公式:
隐藏层计算公式:
\mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h)Ht=ϕ(XtWxh+Ht−1Whh+bh)
输出计算公式:
\mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_qOt=HtWhq+bq
注意:之前我写过这么一篇:手动实现RNN - 掘金 (juejin.cn) 这个没有调用Pytorch的RNN,是自己从零开始写的。本文是调用了人家现成的RNN,两篇文章虽然都是RNN的代码实现,但是二者有本质区别。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
复制代码python人必备导包技术,这段代码不用解释吧。
batch_size, num_steps =32,35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
复制代码设置批量大小batch_size和时间步长度num_step,时间步长度就是可以想象成一个样本中RNN要计算的时间步长度是32。
d2l.load_data_time_machine加载数据集。
注意:这里为了方便,加载数据集时候进行数据预处理,使用的是长度为28的语料库词汇表,不是单词表。词汇表是a~z的字母外加 空格 和<unk>。
设置隐藏层大小的256
在这里RNN层直接使用pytorch提供的RNN。
state = torch.zeros((1, batch_size, num_hiddens))
state.shape
复制代码使用torch.zeros用零向量初始化隐状态。隐状态是三维的,形状是隐状态层数、批量大小、隐藏层大小。
RNN隐状态计算\mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h)Ht=ϕ(XtWxh+Ht−1Whh+bh),这一步就是要初始化\mathbf{H}_{0}H0
使用state.shape看一下\mathbf{H}_{0}H0的形状。
测试一下:
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
复制代码随便搞一个X来试试pytorch自带的rnn层。
X就是随机初始化的,形状是(时间步长、批量大小、语料库词汇表长度)。
使用rnn层进行计算返回Y和state_new,注意这里的Y不是我们说的那个RNN的输出,\mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_qOt=HtWhq+bq,←不是这个玩意儿,是隐藏层,是\mathbf{H}H。
最后一句是输出一下Y和state_new的形状:
(torch.Size([35, 32, 256]), torch.Size([1, 32, 256]))
这里Y是所有的隐状态,state_new是最后一个隐状态。
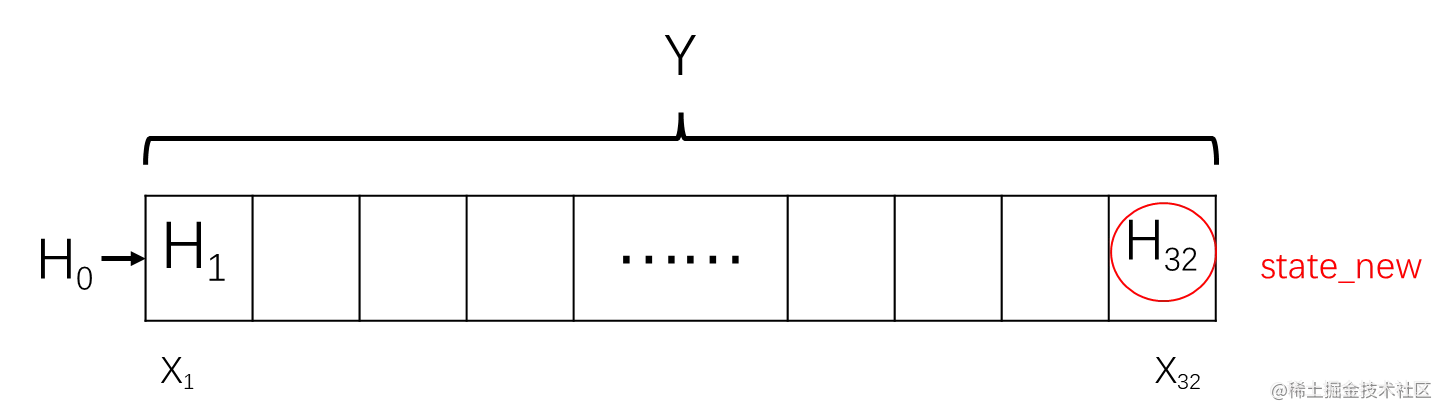
到这里我们可以得出:pytorch自带的RNN层计算的返回值是整个计算过程的隐状态和最后一个隐状态。
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
复制代码这个是完整的RNN模型。
__init__中进行基本设置。
设定RNN层rnn_layer,设定字典大小vocab_size,设定隐藏层大小num_hiddens
然后这个if-else语句,这个语句是为后面准备的。现在这里还是没有什么作用的。因为之后的双向rnn会用到。
not self.rnn.bidirectional也就是说当这个RNN不是双向的时候,进入if语句。此时设定它只有一个隐藏层,并且设定它的vocab_size。反之则进入else语句,此时设定它有两个隐藏层(因为是双向RNN一个正向的一个反向的),并且设定它的vocab_size。
forward设定前向传播函数。
X进行处理,使其变为one-hot向量。再将数据类型转换为浮点型。Y是我们说的隐状态,不是我们常规意义上的输出。output这里,全连接层首先将Y的形状改为(时间步数批量大小, 隐藏单元数)。再输出output输出形状是 (时间步数批量大小, 词表大小)。begin_state设定初始化的函数。里边也是一个if语句。根据rnn的类型来决定初始化的状态。 isinstance(self.rnn, nn.LSTM)是看我们的self.rnn是不是nn.LSTM,如果他只是一个普通的rnn,那就直接对其进行隐藏状态的初始化就可以了;如果他是LSTM的时候,它的隐形状态需要初始化为张量。
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)
复制代码输出:
'time travellerxsszsuxsss'
在训练之前,我们先使用我们大号的模型来看一下它的预测结果。可以看出结果非常不好,因为他后边已经开始重复输出xss了。
如果你的输出和我的输出不一样也没有关系。因为它初始化的时候是随机初始化。所以每次运行的结果可能是不同的。
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
复制代码对其进行训练。500个epoch,学习率设定为1。 这张代码的向量函数中还有一个可视化的函数,所以你在跑这张代码的过程中应该可以看到一个下降的过程图表。的那个坐标跑完了之后再运行下边这个预测输出的代码。
d2l.predict_ch8('time traveller', 10, net, vocab, device)
复制代码输出:
'time travellerit s again'
训练之后再看一下他预测生成的结果。至少比上面那一个靠谱很多。


