 科技公元 后端
2023-05-09
科技公元 后端
2023-05-09
在前面的文章中其实大家也已经看到我使用过collect(Collectors.toList()) 将数据最后汇总成一个 List 集合。
但其实还可以转换成Integer、Map、Set 集合等。
static List<Student> students = new ArrayList<>();
static {
students.add(new Student("学生A", "大学A", 18, 98.0));
students.add(new Student("学生B", "大学A", 18, 91.0));
students.add(new Student("学生C", "大学A", 18, 90.0));
students.add(new Student("学生D", "大学B", 18, 76.0));
students.add(new Student("学生E", "大学B", 18, 91.0));
students.add(new Student("学生F", "大学B", 19, 65.0));
students.add(new Student("学生G", "大学C", 20, 80.0));
students.add(new Student("学生H", "大学C", 21, 78.0));
students.add(new Student("学生I", "大学C", 20, 67.0));
students.add(new Student("学生J", "大学D", 22, 87.0));
}
public static void main(String[] args) {
Optional<Student> collect1 = students.stream().collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge()));
Optional<Student> collect2 = students.stream().collect(Collectors.minBy((s1, s2) -> s1.getAge() - s2.getAge()));
Student max = collect1.get();
Student min = collect2.get();
System.out.println("max年龄的学生==>" + max);
System.out.println("min年龄的学生==>" + min);
/**
* max年龄的学生==>Student(name=学生J, school=大学D, age=22, score=87.0)
* min年龄的学生==>Student(name=学生A, school=大学A, age=18, score=98.0)
*/
}
复制代码Optional,它是一个容器,可以包含也可以不包含值。它是java8中人们常说的优雅的判空的操作。
另一个常见的返回单个值的归约操作是对流中对象的一个数值字段求和。或者你可能想要求 平均数。这种操作被称为汇总操作。让我们来看看如何使用收集器来表达汇总操作。
Collectors类专门为汇总提供了一些个工厂方法:


当然除此之外还有 求平均数averagingDouble、求总数counting等等
我们暂且就先以summingDouble和summarizingDouble来举例吧
案例数据仍然是上面的那些student数据...
求全部学生成绩的总分,求全部学生的平均分。
1、首先使用summingDouble 和 averagingDouble 来实现
Double summingScore = students.stream().collect(Collectors.summingDouble(Student::getScore));
Double averagingScore = students.stream().collect(Collectors.averagingDouble(Student::getScore));
System.out.println("学生的总分==>" + summingScore);
System.out.println("学生的平均分==>" + averagingScore);
/**
* 学生的总分==>823.0
* 学生的平均分==>82.3
*/
复制代码2、使用summarizingDouble来实现
它更为综合,可以直接计算出相关的汇总信息
DoubleSummaryStatistics summarizingDouble = students.stream().collect(Collectors.summarizingDouble(Student::getScore));
double sum = summarizingDouble.getSum();
long count = summarizingDouble.getCount();
double average = summarizingDouble.getAverage();
double max = summarizingDouble.getMax();
double min = summarizingDouble.getMin();
System.out.println("sum==>"+sum);
System.out.println("count==>"+count);
System.out.println("average==>"+average);
System.out.println("max==>"+max);
System.out.println("min==>"+min);
/**
* sum==>823.0
* count==>10
* average==>82.3
* max==>98.0
* min==>65.0
*/
复制代码但其实大家也都发现了,使用一个接口能够实现,也可以拆开根据自己的所需,选择合适的API来实现,具体的使用还是需要看使用场景。
Joining,就是把流中每一个对象应用toString方法得到的所有字符串连接成一个字符串。
如果这么看,它其实没啥用,但是Java也留下了后招,它的同伴(重载方法)提供了一个可以接受元素之间的分割符的方法。
String studentsName = students.stream().map(student -> student.getName()).collect(Collectors.joining());
System.out.println(studentsName);
String studentsName2 = students.stream().map(student -> student.getName()).collect(Collectors.joining(","));
System.out.println(studentsName2);
/**
* 学生A学生B学生C学生D学生E学生F学生G学生H学生I学生J
* 学生A,学生B,学生C,学生D,学生E,学生F,学生G,学生H,学生I,学生J
*/
复制代码对于对象的打印:
// 不过对于对象的打印 个人感觉还好 哈哈
String collect = students.stream().map(student -> student.toString()).collect(Collectors.joining(","));
System.out.println(collect);
System.out.println(students);
/**
* Student(name=学生A, school=大学A, age=18, score=98.0),Student(name=学生B, school=大学A, age=18, score=91.0),Student(name=学生C, school=大学A, age=18, score=90.0),Student(name=学生D, school=大学B, age=18, score=76.0),Student(name=学生E, school=大学B, age=18, score=91.0)....
* [Student(name=学生A, school=大学A, age=18, score=98.0), Student(name=学生B, school=大学A, age=18, score=91.0), Student(name=学生C, school=大学A, age=18, score=90.0), Student(name=学生D, school=大学B, age=18, score=76.0)..)]
*/
复制代码但其实我还有一些没有讲到的API使用方法,大家也可以额外去尝试尝试,这其实远比你看这篇文章吸收的更快~
就像数据库中的分组统计一样~
举个例子,我想统计每个学校有哪些学生
我是不是得设计这样的一个数据结构Map<String,List<Student>>才能存放勒,我在循环的时候,是不是每次都得判断一下学生所在的学校的名称,然后看是否要给它添加到这个List集合中去,最后再put到map中去呢?
看着就特别繁琐,但是在 stream 中就变成了一行代码,其他的东西,都是 Java 内部给你优化了。
// 我想知道每所学校中,学生的数量及相关信息,只要这一行代码即可
Map<String, List<Student>> collect = students.stream().collect(Collectors.groupingBy(Student::getSchool));
System.out.println(collect);
/**
* {大学B=[Student(name=学生D, school=大学B, age=18, score=76.0), Student(name=学生E, school=大学B, age=18, score=91.0), Student(name=学生F, school=大学B, age=19, score=65.0)],
* 大学A=[Student(name=学生A, school=大学A, age=18, score=98.0), Student(name=学生B, school=大学A, age=18, score=91.0), Student(name=学生C, school=大学A, age=18, score=90.0)],
* 大学D=[Student(name=学生J, school=大学D, age=22, score=87.0)],
* 大学C=[Student(name=学生G, school=大学C, age=20, score=80.0), Student(name=学生H, school=大学C, age=21, score=78.0), Student(name=学生I, school=大学C, age=20, score=67.0)]}
*/
复制代码有些时候这真的是十分有用且方便的。
但是有时候我们往往不止于如此,假如我要统计每个学校中20岁年龄以上和20以下的学生分别有哪些学生,那么我的参数就不再是Student::getSchool了,而是要加上语句了。那么该如何编写呢?
//统计每个学校中20岁年龄以上和20以下的学生分别有多少
Map<String, List<Student>> collect = students.stream().collect(Collectors.groupingBy(student -> {
if (student.getAge() > 20) {
return "20岁以上的";
}
return "20以下的";
}));
System.out.println(collect);
复制代码如果要统计每个学校有多少20岁以上和20岁以下的学生的信息,其实也就是把 return 语句修改以下即可。
//统计每个学校中20岁年龄以上和20以下的学生分别有多少
Map<String, List<Student>> collect = students.stream().collect(Collectors.groupingBy(student -> {
if (student.getAge() > 20) {
return student.getSchool();
}
return student.getSchool();
}));
System.out.println(collect);
复制代码相信大家也看出来groupingBy中的 return 语句就是 Map 中的key值
但其实groupingBy()并不只是一个人,它也有兄弟姐妹
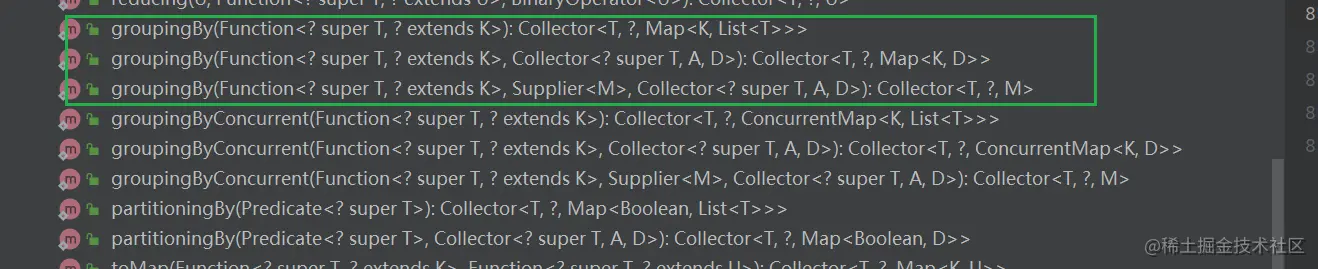
假如我想把上面的例子再改造改造,
改为:我想知道20岁以上的学生在每个学校有哪些学生,20岁以下的学生在每个学校有哪些学生。
数据结构就应当设计为Map<String, Map<String, List<Student>>> 啦,第一级存放 20岁以上以下两组数据,第二级存放以每个学校名为key的数据信息。
Map<String, Map<String, List<Student>>> collect = students.stream().collect(Collectors.groupingBy(Student::getSchool, Collectors.groupingBy(student -> {
if (student.getAge() > 20) {
return "20以上的";
}
return "20岁以下的";
})));
System.out.println(collect);
/**
* {大学B={20岁以下的=[Student(name=学生D, school=大学B, age=18, score=76.0),Student(name=学生E, school=大学B, age=18, score=91.0), Student(name=学生F, school=大学B, age=19, score=65.0)]},
* 大学A={20岁以下的=[Student(name=学生A, school=大学A, age=18, score=98.0), Student(name=学生B, school=大学A, age=18, score=91.0), Student(name=学生C, school=大学A, age=18, score=90.0)]},
* 大学D={20以上的=[Student(name=学生J, school=大学D, age=22, score=87.0)]},
* 大学C={20以上的=[Student(name=学生H, school=大学C, age=21, score=78.0)],20岁以下的=[Student(name=学生G, school=大学C, age=20, score=80.0), Student(name=学生I, school=大学C, age=20, score=67.0)]}}
*/
复制代码这里利用的就是把一个内层groupingBy传递给外层groupingBy,俗称的套娃~
外层Map的键就是第一级分类函数生成的值,而这个Map的值又是一个Map,键是二级分类函数生成的值。
之前我的截图中,groupingBy的重载方法中,其实对于第二个参数的限制,并非说一定是要groupingBy类型的收集,更抽象点说,它可以是任意的收集器~
再假如,我的例子改为:
我现在明确的想知道每个学校20岁的学生的人数。
那么这个数据结构就应当改为
Map<String,Long>或者是Map<String,Integer>呢?
那么在这里该如何实现呢?
Map<String, Long> collect = students.stream().collect(Collectors.groupingBy(Student::getSchool, Collectors.counting()));
System.out.println(collect);
/**
* {大学B=3, 大学A=3, 大学D=1, 大学C=3}
*/
复制代码实际上还有许多未曾谈到的东西,这里都只是非常简单的应用,对于其中的流的执行的先后顺序,以及一些简单的原理,都没有过多的涉及,大家先上手用着吧~
我这里只是阐述了一些比较简单的应用性操作,未谈及设计思想之类,但是要明白那种才是更值得去阅读和理解的。


