 码农老张 后端
2023-05-17
码农老张 后端
2023-05-17
volatile 是 Java 并发编程中一个非常重要,也是面试常问的一个技术点,用起来很简单直接修饰在变量前面即可,但是我们真的懂这个关键字吗?它在 JVM 底层,甚至在 CPU 层面到底是如何发挥作用的?
为了彻底弄清楚这个关键字,衍生出了一系列问题,真的折磨了我好几天,因为这东西往底层涉及到的知识太多了,而网上很多资料也说法不一,根本不知道哪个是正确的......
volatile 用于修饰一个成员变量,可以控制变量的可见性,即一个线程修改了这个变量之后,其他线程能够绝对立即可见。
arduino复制代码static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (flag){
}
System.out.println("验证了可见性");
},"Thread A").start();
Thread.sleep(1000);
flag = false;
}
会发现在主线程中对 flag 变量进行修改,但是 Thread A 中无法监听到最新值,导致 Thread A 中无法跳出循环。当我们给 flag 用 volatile 修饰之后
arduino复制代码static volatile boolean flag = true;
再执行上面的例子发现 Thread A 中就可以监听到主线程对于 flag 的修改,及时结束循环。这说明 volatile 实现了多线程之间变量的可见性。
很多人喜欢用上面的例子来说明 volatile ,真的这么简单吗?这个结论正确吗?
上面的例子是极端情况,假如我们在 Thread A 的循环中加一行代码
bash复制代码Thread.sleep(1);
//或者 System.out.println("test");
你会发现即使我们不给变量 flag 修饰 volatile ,也能结束循环,监听到主线程对于 flag 变量的修改,嘿奇不奇怪?,对于这个问题我找了很多资料,看了很多文章和视频,终于有了正确答案。但是在说这个正确答案之前,我想分享一下我的分析历程。
Java 内存模型 (Java Memory Model) 简称 JMM,是 JSR133 规范中定义的一种抽象概念,它定义了一系列规范,规范了 Java 程序中线程如何访问内存。
一句话概括,就是对于 Java 程序来说,你要按照它定的规范去访问内存。
这里的工作内存其实一个逻辑概念,可能只是寄存器, 可能是寄存器+缓存, 也可能是多级缓存。我们可以依次打开 任务管理器 → 性能 → CPU 看到下面这张图
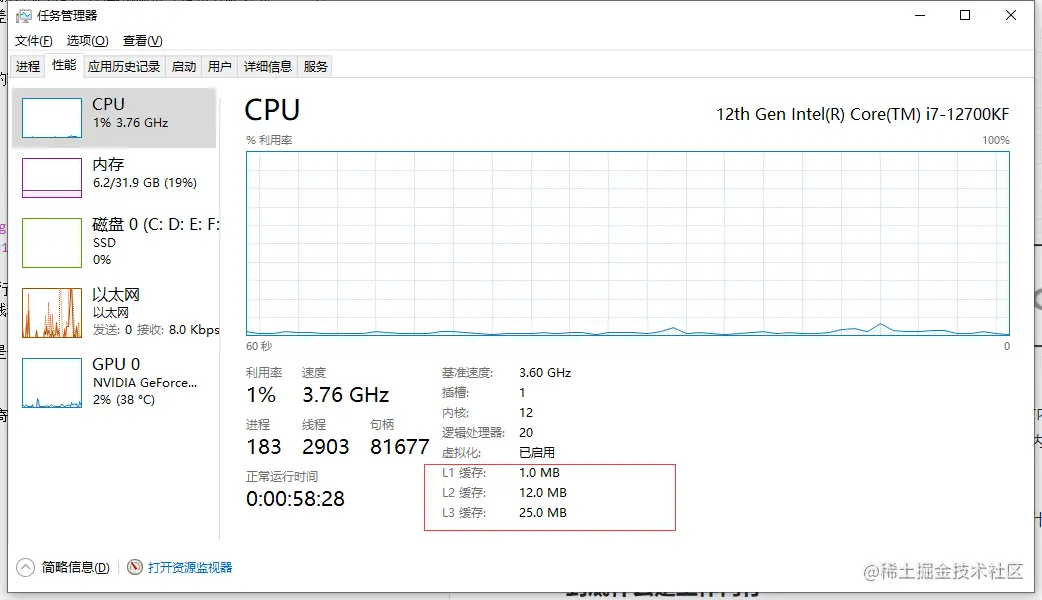
这里我框出来的就是 CPU 的三级缓存,工作内存通常是这一块内存,这里的计算速度大约是普通运行时内存的 100 倍。为什么会有缓存呢,这是由于寄存器和内存读取速度相差太大,直接操作内存的话 CPU 要等内存响应,浪费了 CPU 昂贵的资源,所以有了缓存来提高性能,其实这原理就和我们开发中使用缓存中间件是一样的。

那么有意思的问题就来了,既然三级缓存速度这么快为什么不直接把内存条都用这个三级缓存呢?因为贵嘛~~~
在 Java 程序运行时, CPU 和内存(常说的堆)是按下图的流程进行交互的,从共享内存将数据读到自己的工作内存然后操作自己工作内存中的副本,完了再同步到主内存。
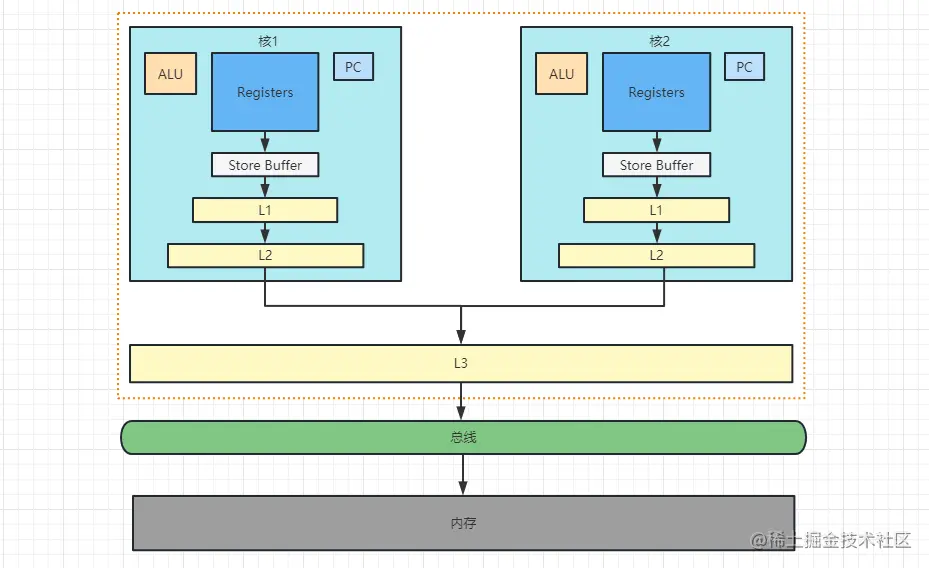
那么现在就会有一个问题,假设主内存有个变量 x = 0 ,两个线程并行修改数据自增,然后都要写回主内存,预期结果是 2,CPU0 和 CPU1 没法互相感知对方的改动,都把自己的结果写回主内存。预期结果是 2 现在变成了 1。于是为了解决多核 CPU 的数据不一致问题,出现了基于总线嗅探的缓存一致性协议技术。
总线嗅探这个策略,本质上就是把所有的读写请求都通过总线广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应,相当于消息队列广播消息。
当其他 CPU 核心嗅探到缓存中的数据被别的 CPU 修改了,会将这份数据置为失效状态,基于这个失效的操作实现了一些缓存一致性协议例如 MSI、MESI、DragonProtocol 等,其中以 intel CPU 为代表的是 MESI。
MESI 缓存一致性协议动画展示 这个动画很生动的展示了 MESI 的工作过程。关于 MESI 的更多细节这里不过多谈论,有兴趣可以去找一些资料深入理解。
Store Buffer 是这个问题的最后一个知识点。CPU 在写入共享数据时,为了避免等待其他 CPU 核心的失效响应(因为这个过程需要通过总线发信号过去再接收回来的结果,对于 CPU 来说这个过程太长了),直接把数据写入到 Store Buffer 中,同时发送 Invalidate 消息,然后继续去处理其他指令。当收到其他所有CPU 发送的 Invalidate Acknowledge 消息时,再将 Store Buffere 中的数据写到缓存中,然后再从缓存同步到主内存。
由 Store Buffer 我们可以知道,只有当收到其他 CPU 的 Invalidate Acknowledge 之后,当前 CPU 才能把自己做的修改写到缓存,我们的示例中 while(flag){} 死的循环体没有给 Thread A 的 CPU 让出任何时间,所以 它没法做出 Invalidate 响应,也就是说对于 Thread A 这个线程的CPU 来说,高速缓存一直没有失效。所以它读取的一直都是旧值。
也就是说只要我们给 CPU 让出一点点时间片,默认的缓存一致性协议就能帮我们实现可见性,比如休眠,哪怕是 1ms,或者加一行输出语句(因为输出语句涉及到 IO 操作,IO 操作是 CPU 委托给 DMA 去做的),
如果上述认知是正确的,那么基于缓存一致性协议就可以认为一开始的代码示例中,主线程并没有将 flag = false 写到主内存,因为它一直收不到 Thread A 这个线程的 Invalidate Acknowledge。
我们写代码证明,在主线程中再开启一个线程,如果这个线程能够执行到打印语句,那么说明 flag 的值被主线程写回到了主内存。
arduino复制代码static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (flag){
//Thread.sleep(1);
}
System.out.println("验证了可见性1");
},"Thread A").start();
Thread.sleep(1000);
flag = false;
Thread.sleep(10);
new Thread(() -> {
while (flag){
//Thread.sleep(1);
}
System.out.println("验证了可见性2"); //如果打印这句话,则说明 flag 的值已经写回主内存,或者说至少已经写到主线程那颗 CPU 的高速缓存中
},"Thread B").start();
}
结果打印了 验证了可见性2,这说明 flag = false 已经被写到了主内存中,然后我就崩溃了,这他妈到底啥原因啊!!!

经过我的不懈努力,终于在某篇文章找到了本质原因,居然是在于 Java即时编译器(JIT) 将 while 这部分代码做了优化。while(flag) 为 true 的次数过多时,JIT 直接将 while(flag) 默认为 while(true)。

我们可以通过增加 JVM 参数 -Xint 关闭 JIT 优化。这样不加 volatile 也能使程序停止下来。于是我验证了一下确实是这样,至此纠结我几天的问题终于解决了。
这个问题我请教过很多朋友,他们都不知道,还说我研究的太深了......但是我这个人啊,遇到问题就非得搞清楚,不然就浑身难受啊~~~ 折磨了我几天的问题终于搞懂了,柳暗花明。
不过新的问题又出现了,既然这样,volatile 的作用又是什么?......因为这里本质上加不加 volatile 其实都能实现可见性啊?这个等会说


其实缓存失效的交互都是通过总线发信号的,当 CPU1 要告诉 CPU0 你的缓存要失效了,通过总线发一个信号过去修改 CPU0 的缓存行地址, CPU0 通过总线嗅探感知到缓存行地址被修改就会再通过总线回一个 Invalidate Acknowledge 消息,这个过程不会占用 CPU0 的时间片。
首先可以确定的一点是 JIT 不会对加了 volatile 关键字的变量的相关代码进行优化。加了 volatile 之后我们使用 javap -v 的命令反编译之后可以看到这个变量的 flags 中多了一个标识 ACC_VOLATILE 。这个东西在调用到 C++ 代码是这样的
arduino复制代码inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
__asm__ 代表这是汇编指令
最终到 CPU 汇编指令之后是一个 lock; addl $0,0(%%rsp),通过查阅
8.1.4 Effects of a LOCK Operation on Internal Processor Caches For the Intel486 and Pentium processors, the LOCK# signal is always asserted on the bus during a LOCK operation, even if the area of memory being locked is cached in the processor. For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory location internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more processors that have cached the same area of memory from simultaneously modifying data in that area.
翻译过来
LOCK 操作对处理器内部缓存的影响对于Intel486和Pentium处理器,在LOCK操作期间,LOCK信号总是在总线上被断言,即使被锁定的内存区域缓存在处理器中。对于P6和最新的处理器系列,如果在LOCK操作期间被锁定的内存区域作为回写内存缓存在正在执行LOCK操作的处理器中,并且完全包含在缓存线中,处理器可能不会在总线上断言LOCK信号。相反,它将在内部修改内存位置,并允许它的缓存一致性机制,以确保操作是原子地执行的。这种操作称为“缓存锁定”。缓存一致性机制自动防止两个或多个缓存了相同内存区域的处理器同时修改该区域的数据
也就是说在新的 CPU 中这个指令控制的是锁定缓存行。LOCK 命令的作用
Store Buffer 写进缓存,不需要发送 Invalidate 消息给其他 CPU。并且通过总线强制使其他 CPU 的该数据缓存立即失效。在锁定期间,其他CPU不能同时缓存此数据所以 volatile 最终实现可见性的原理是汇编指令 LOCK 。然后我们说 volatile 实现可见性这个结论肯定是没错的,但是它实现的是基于 JMM 内存规范上的可见性,就是说这是 JMM 层面的,在 CPU、高速缓存、主内存之间的可见性是通过缓存一致性协议去实现的。
那么说到这里我们可以得出一个结论,volatile 和缓存一致性协议有关系吗?因为很多文章和视频在说 volatile 的时候都会提到 MESI ,更有甚者说 volatile 关键字底层触发了缓存一致性协议 MESI 。。。
这个要说有也有,说没有也没有,缓存一致性协议是硬件层面保障多核 CPU 之前缓存数据一致性的技术,volatile 是实现 JMM 层面可见性的技术,只能说 volatile 底层通过汇编指令 LOCK 用到了本来就客观存在的缓存一致性协议技术。
内存屏障, 是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。
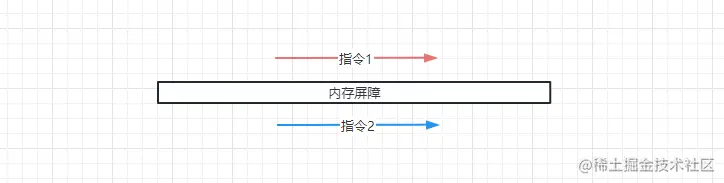
其实就是在两个指令之间插入了一个东西限制了上面的指令无法跑到下面这条指令后面,下面这条指令也无法跑到上面这条指令前面,如上图。
内存屏障的出现是为了解决多个 CPU 之间的乱序执行问题,同一个 CPU 的指令已经通过 Store Buffer 保证顺序执行了,但 Store Buffer 无法保证多个 CPU 存在共享数据时指令的顺序执行
我们可以看一个经典的示例来验证重排序
ini复制代码static int x = 0, y = 0;
static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
for (; ; ) {
x = 0;y = 0;a = 0;b = 0;
Thread one = new Thread(() -> {
a = 1;
x = b;
});
Thread two = new Thread(() -> {
b = 1;
y = a;
});
one.start();two.start();one.join();two.join();
System.out.println("x:" + x + ",y:" + y);
//0,1 1,0 1,1
if (x == 0 && y == 0) {
break;
}
}
System.out.println("验证了重排序");
}
我们假设多 CPU 之间的指令不会发生重排序那么这个程序的结果只能有三个,x=0,y=1;x=1,y=0;x=1,y=1;但是执行结果并不是,这说明会发生指令重排序,如果想从 Store Buffer 层面深究可以看文末贴出的参考文章。
注意指令重排序是 CPU 层面的概念,不是 Java 层面的。
内存屏障本身是 CPU 指令层面的概念,不过在 JVM 层面,它定出了自己的规范去对 CPU 层面的内存屏障做出一层封装。
在 JVM 层面,JVM 规范要求实现者必须实现下面四种逻辑上的内存屏障(Load 代表读取变量,Store 代表修改变量)
LoadLoad : 对于这样的语句 Load1;LoadLoad;Load2;,在 Load2 以及后续读取操作要读取的数据被访问前,保证 Load1 要读取的数据被读取完毕StoreStore:对于这样的语句 Store1;StoreStore;Store2;,在 Store2 以及后续写入操作执行前,保证 Store1 的写入操作对其他处理器可见LoadStore :对于这样的语句 Load1;LoadStore;Store2;,在 Store2 以及后续写入操作被刷出前,保证 Load1 要读取的数据被读取完毕StoreLoad:对于这样的语句 Store1;StoreLoad;Load2;,在 Load2 以及后续所有读取操作执行前,保证Store1 的写入对所有处理器可见这个就很简单了,上面我们已经知道了 volatile 最底层是汇编指令 LOCK,该指令本身就提供了内存屏障的功能,所以只需要在 JVM 层面调用该指令实现内存屏障即可。
在 volatile 的实现中被它修饰的变量在读写的时候前后会加内存屏障,其规则是
| 操作 | 作用 |
|---|---|
| 在每个 volatile 读操作的后面插入一个 LoadLoad | 禁止处理器把上面 volatile 读与下面的普通读重排序 |
| 在每个 volatile 读操作的后面插入一个 LoadStore | 禁止处理器把上面 volatile 读与下面的普通写重排序 |
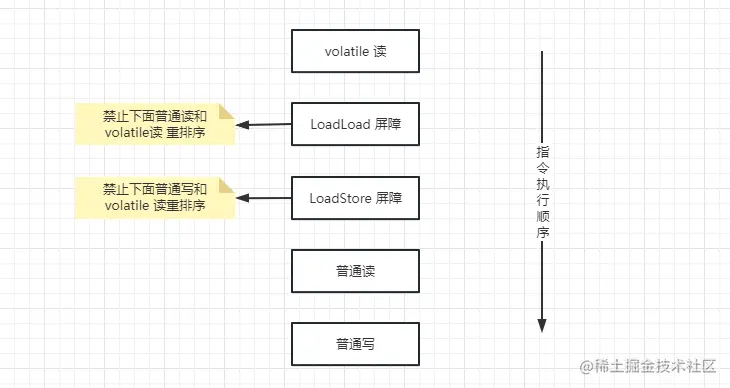
| 操作 | 作用 |
|---|---|
| 在每个 volatile 写操作的前面插入一个 StoreStore | 保证 volatile写 之前,前面的所有普通写操作都已经刷新主内存 |
| 在每个 volatile 写操作的后面插入一个 StoreLoad | 避免 volatile写 与后面可能有的 volatile读/写操作重排序 |

不管是哪个屏障,这都是 JVM 层面的逻辑实现,在最底层还是通过 CPU 汇编指令 LOCK 去实现的。
其实这个问题挺搞笑的,如果你问一个东西为什么能达到某个效果,那倒是可以聊聊底层,你这问它为啥不能保证原子性,本来就不能有啥为什么呢。。。
从上面内存模型和内存交互的知识,我们能知道,当对一个 volatile 变量进行写的时候会锁定缓存行,将值立马刷新到主内存,但是这个操作又不会影响已经被读到其他 CPU 寄存器内的值。举个例子,
volatile 变量 x 读到的值是 0,此时 CPU0 的高速缓存中缓存的值也是 0x 执行 +1 计算得到的值 x=1x 进行写,把值改为 1,然后将 CPU0 的缓存置为失效,将 x=1 写到主内存x=1 写到 Store Buffer,将 CPU1 的缓存失效,将 x=1 写到缓存,进而写到主内存这不就是一个正常可能出现的过程么,所以本来就是不能保证原子性的。
至此我花了一个星期去学习了很多硬件底层方面的知识,文章篇幅有限无法详细的说透每个知识点,虽然花了一个星期的时间证明出来一个错误的结论,但是这个过程让我学到了很多底层技术,还是很值得的。
总而言之,volatile 的作用


