 宙斯科技 后端
2024-03-27
宙斯科技 后端
2024-03-27
目前,KV 存储的广泛使用极大程度上源于快速访问的业务需求,而这种业务通常对时延敏感度高,在较好的平均性能下,还需要解决特定场景下的性能抖动。开源 Redis 在 AOF 重写、RDB、主从同步等操作时,为不影响主线程,采用 fork 创建子线程去执行,但由于主线程仍在提供服务,触发 Copy-On-Write 时会引起性能抖动,导致长尾时延。
华为云 GeminiDB(原华为云 GaussDB NoSQL,后统称为 GeminiDB)是采用存算分离架构的 NoSQL 多模数据库,在性能、稳定性方面业界领先。KV 接口上,GeminiDB 100%兼容 Redis 5.0 协议,用户无需修改代码即可平迁到 GeminiDB。针对业界的 Redis fork 技术痛点,GeminiDB 提供了终极的优化方案。
我们先来看下业界的两种通用解法:
业界解法一
实现层面优化 fork 问题
常规的解决方案是在 fork 实现层进行魔改,也就是找到造成 fork 长尾时延的代码所在然后对其进行优化。通过多次实验发现,fork 的执行时间随着实例大小增长而剧增,其中最耗时的是页表拷贝操作,如下图(a)所示,在 Invoke Fork 操作之后,主进程需要花时间进行页表拷贝,服务出现毛刺现象。
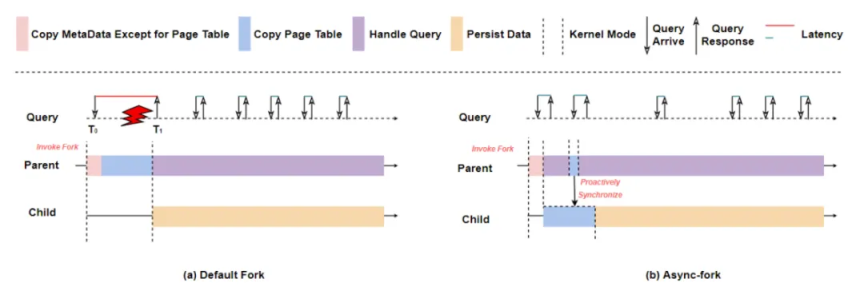
由此产生 fork 重写的核心思路:由于父进程在 fork 原生内部实现中并不纯粹,其在页表复制时仍需陷入内核态,出现短暂阻塞现象。通过将父进程耗时占比最高的页拷贝操作移至子进程去执行,足以大幅削弱父进程在 fork 过程中的阻塞现象,从而可以在对程序无任何修改的条件下解决原生 fork 带来的长尾时延。
业界有种算法,如上图(b)所示,可以通过让子进程去异步完成页表拷贝动作(Copy Page Table)和主进程主动同步页表(Proactively Synchronize)来解决毛刺以及主子进程的可能不一致问题,可以做到主进程近乎零阻塞。不难看出,修改 fork 算法有以下几点优势:
1. 实现层面消除了 fork 场景带来的长尾时延。
2. 对内存型键值存储服务完全透明。
但由于涉及魔改操作系统 fork 实现,导致维护和演进成本较高,向前兼容性较差。相比之下,在架构层面去解决这个问题,或许更加简单且自然。
业界解法二
架构层面优化 fork 问题
除了针对 fork 的优化,直接消除 fork 或许是工程上更加迫切的需要。
我们分析一下,之所以会有 fork 的引入,是因为 Redis 做了 AOF 重写、RDB、主从同步的操作。恰恰对于 Redis 这种内存型 KV 存储而言,AOF 操作可以保证了数据不丢,而 RDB 和主从同步也是其持久化需要。但如果是非易失型 KV 存储,从内存到持久化介质的链路就不存在,类 RDB 和类主从同步操作也就可以交给存储层独立解决,从而彻底消除 fork 所带来的长尾时延。
基于此,业界有些数据库将 KV 数据通过其存储引擎直接写入持久化介质中,且在计算层做了性能上的高度优化,达到了不劣于开源 Redis 的性能:
以 PMem 为存储底座的存算分离架构
采用 PMem 作为其主要持久化存储介质的存储引擎,在某种程度上来说,其兼具 DRAM 的性能和字节寻址能力以及 SSD 的可持久化特性。下图是几种存储介质的对比:

同时,通过实现存储引擎的 Cache 模块,在服务运行期间存放业务热数据的数据页会被加载到 PMem 上,在处理用户请求期间不再直接操作 SSD 上的数据页,而是操作读写延迟更低的 PMem,使得计算层的性能以及吞吐量得到了进一步的提升。
总的来说,使用 PMem 存储底座的优势在于:
1. 没有 fork 场景,不存在 fork 带来的长尾时延。
2. 提供了比开源 Redis 更大的容量。
3. 数据可冷热分级存储。
但是,强依赖 PMem 也带来了一些难以解决的问题:
1. 非易失型内存编程难度高且鲁棒性差,需要框架和工具层面去降低其开发难度,总的来说,开发和维护成本过高。
2. 由于编程复杂,而且 Redis 索引结构繁多,数据模型相关 API 高达 300 多个,造成 Redis 命令兼容的实现可靠性极具下降,同样面临如何降低编码复杂度的问题。
3. PMem 相比于 DRAM 有数量级的性能下降,在读性能上有 3 倍以上的性能下降以及 10 倍以上的带宽减少,性能问题不可忽视。
在可靠性和开发维护成本上,以 PMem 为存储底座的架构还是有一定不足之处。
华为云的 NoSQL 数据库 GeminiDB 在这方面有更加强大的实现方案。GeminiDB 兼容 Redis 接口(原 GaussDB(for Redis),后统称为 GeminiDB 兼容 Redis 接口),以 RocksDB+分布式文件系统+高性能存储池为底座,实现了领先的存算分离架构,综合表现更佳。
三、华为云 GeminiDB 方案介绍
GeminiDB 存算分离架构
华为云 GeminiDB 兼容 Redis 接口,存储架构采用 RocksDB+分布式文件系统+高性能存储池,如下图所示,在架构层面消除了长尾时延的影响外,通过高性能存储池提供高可靠存储特性,分布式文件系统封装高性能存储池向外暴露类标准文件系统接口,降低开发难度。
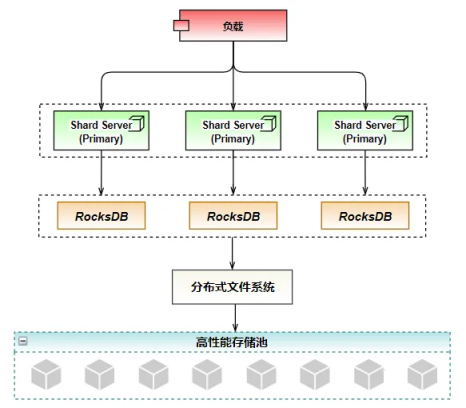
而在性能选择方面,选择 RocksDB 作为存储引擎。它针对快速、低延迟的存储进行了优化,具有极高的写入吞吐。同时,RocksDB 支持预写日志,范围扫描和前缀搜索,在高并发读写以及大容量存储时能够提供一致性的保证。RockDB 的追加写特征恰好解决了磁盘 I/O 最耗时磁盘寻道时间,达到了接近内存随机读写的性能。
高可靠的实现,选择华为研发的高性能存储池分布式存储,最高支持 128TB 的海量存储,支持跨 AZ 部署、故障秒级切换,保证了在极度恶劣的情况的数据无损和快速恢复,支持数据的自动备份。
除此之外,分布式文件系统借助 HDFS Snapshot 实现了秒级快照,产生整个文件系统或某个目录在某个时刻的镜像,向用户提供了数据恢复、数据备份、数据测试的能力。
简言之,通过 RocksDB+分布式文件系统+高性能存储池的存储架构,已经做到:
1. 低时延,基于高性能的存储架构,访问时延有了高度保障。
2. 大容量,基于存算分离,存储层可自由扩容。
3. 低成本,基于冷热数据分级存储,贴合客户诉求。
4. 高可靠, 基于分布式文件系统+高性能存储池,支持优秀的数据备份和数据同步特性,且不对主进程造成时延影响。
不过,RocksDB 的数据存储模式也会带来一些复杂性。由于 RocksDB 存在读、写和空间放大的问题,且三者相互制约。尽管 RocksDB 提供了多种 Compaction 策略和参数以适应不同应用场景,但由于影响因子过多,策略的选择和调参成本会比较高。
小结
通过不同解决方案之间的对比,在解决长尾时延的问题上,架构解决方案更加贴合大多数客户诉求。同时,在大部分场景下,GeminiDB 兼容 Redis 接口的架构相比于业界方案提供了更高的可靠性和良好的性能表现,预计年底可达到单片百万 QPS 的性能水平。
开年采购季云数据库特惠
活动时间:3月1日-31日
云数据库新用户1年19元起
不限新老1年6.5折起


