 宅哥聊构架 数据库
2024-08-20
宅哥聊构架 数据库
2024-08-20

随着业务量的增长,高并发,数据库服务器宕机等问题频繁出现,单台MySQL服务器将会成为系统瓶颈。
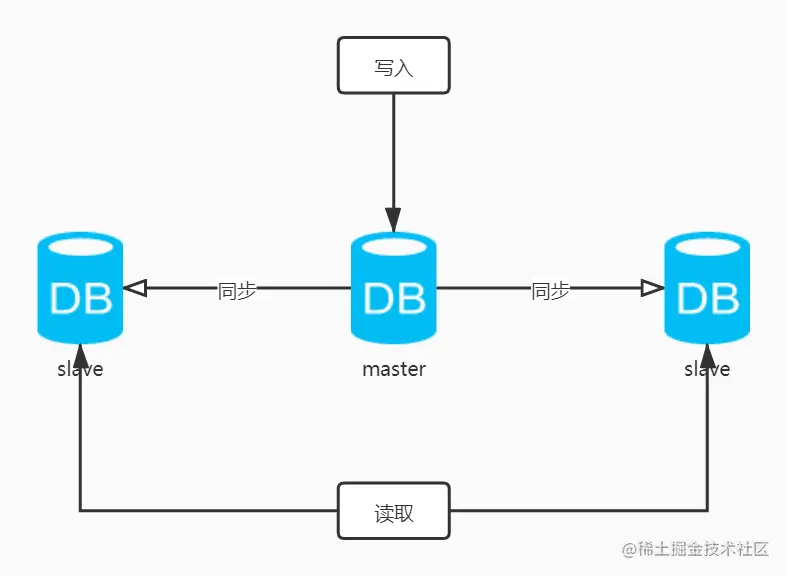
为了解决此问题,通常会使用集群主从同步模式(Master-Slave)来同步数据,通过读写分离(MySQL-Proxy)来提升数据库的并发负载能力。
总结主从同步模式优势:
MySQL主从之间数据同步主要通过 binlog 日志实现。
主要用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中,可以简单理解为记录的就是sql语句;
在实际应用中, binlog 的主要使用场景有两个:
binlog 日志有三种格式,分别为 Statement 、 Row 和 Mixed;
在 MySQL 5.7.7 之前,默认的格式是 Statement , MySQL 5.7.7 之后,默认值是 Row;
Statement格式 -- 基于SQL语句的复制,每一条会修改数据的sql都会记录在binlog中
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能;
缺点:由于记录的只是执行语句,但由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数(比如 uuid() 函数)之类的语句无法被记录复制;
Row格式 -- 基于行的复制,记录单元为每一行的改动,基本是可以全部记下来
优点:会记录每次操作的源数据与修改后的目标数据,绝对精准的还原,从而保证了数据的安全与可靠,并且复制和数据恢复过程可以是并发进行的;
缺点:可能会导致大量行的改动(比如alter table),这种模式的文件保存的信息太多,日志量太大;
Mixed格式* *-- 一种折中的方案,普通操作使用Statement记录,当无法使用Statement的时候使用Row
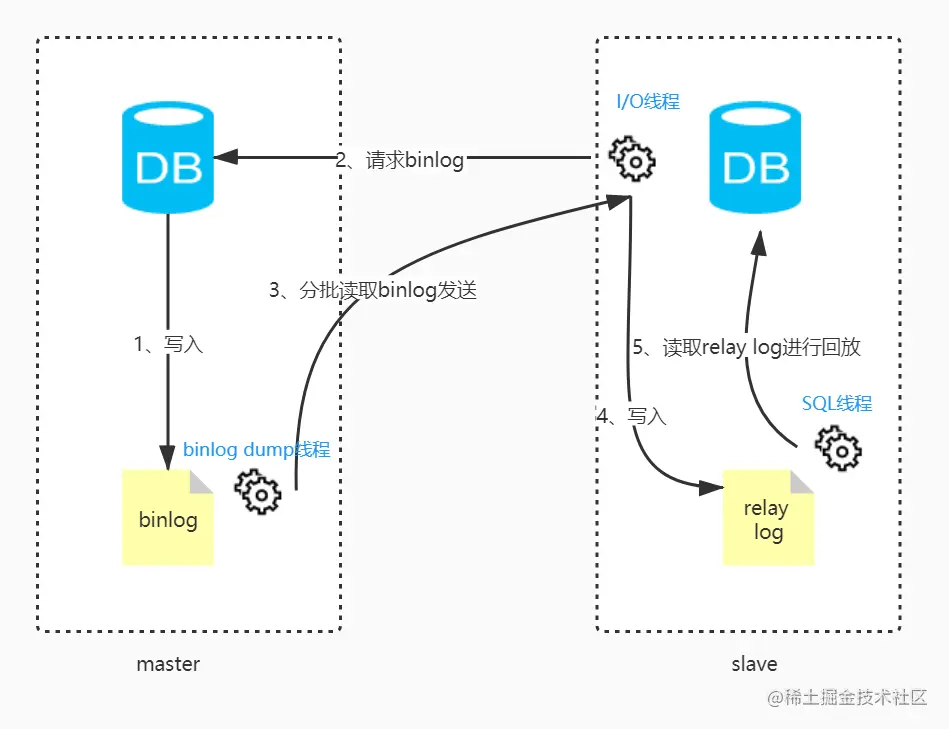 MySQL主从复制需要三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread)
MySQL主从复制需要三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread)
基本过程总结
master库上的数据发生改变时,则将其改变写入binlog中;
slave库在一定时间间隔内对master进行binlog探测是否发生改变,如发生改变,则开启I/O线程连接Master事件,请求从执行binlog日志文件中的指定位置,开始读取binlog至slave库;
master库接收到从库的IO线程请求后,其上复制的dump线程会根据Slave的请求信息分批读取binlog文件然后返回给从库的IO线程;
slave库的I/O线程获取到master库上IO线程发送的日志内容后,会将binlog日志内容依次写到slave库的relay Log(即中继日志)文件的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master库binlog日志时能告诉master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容;
slave库服务器的SQL线程会实时监测到本地relay log中新增了日志内容,然后把relay log中的日志翻译成SQL并且按照顺序执行SQL来更新从库的数据。
根据前面主从复制的原理可以看出,两者之间是存在一定时间的数据不一致,也就是所谓的主从延迟。
我们来看下导致主从延迟的时间点:
那么所谓主从延迟,就是同一个事务,从库执行完成的时间和主库执行完成的时间之间的差值,即T3-T1。
我们也可以通过在从库执行show slave status,返回结果会显示seconds_behind_master,表示当前从库延迟了多少秒。
seconds_behind_master如何计算的?
seconds_behind_master,也就是前面所描述的T3-T1。为什么会主从延迟?
正常情况下,如果网络不延迟,那么日志从主库传给从库的时间是相当短,所以T2-T1可以基本忽略。
最直接的影响就是从库消费中转日志(relay log)的时间段,而造成原因一般是以下几种:
1、从库的机器性能比主库要差
比如将20台主库放在4台机器,把从库放在一台机器。这个时候进行更新操作,由于更新时会触发大量读操作,导致从库机器上的多个从库争夺资源,导致主从延迟。
2、从库的压力大
按照正常的策略,读写分离,主库提供写能力,从库提供读能力。将进行大量查询放在从库上,结果导致从库上耗费了大量的CPU资源,进而影响了同步速度,造成主从延迟。
3、大事务的执行
一旦执行大事务,那么主库必须要等到事务完成之后才会写入binlog。比如主库执行了一条insert … select非常大的插入操作,该操作产生了近几百G的binlog文件传输到只读节点,进而导致了只读节点出现应用binlog延迟。
因此,DBA经常会提醒开发,不要一次性地试用delete语句删除大量数据,尽可能控制数量,分批进行。
4、主库的DDL(alter、drop、create)
只读节点与主库的DDL同步是串行进行,如果DDL操作在主库执行时间很长,那么从库也会消耗同样的时间,比如在主库对一张500W的表添加一个字段耗费了10分钟,那么从节点上也会耗费10分钟。
5、锁冲突
锁冲突问题也可能导致从节点的SQL线程执行慢,比如从机上有一些select .... for update的SQL等。
主从同步问题永远都是一致性和性能的权衡,得看实际的应用场景,若想要减少主从延迟的时间,可以采取下面的办法:
在高并发场景或者网络不佳的场景,如果存在较大的主从同步数据延迟,这时候读请求去读从库,就会读到旧数据。这时候最简单暴力的方法,就是强制读主库。实际上可以使用缓存标记法。
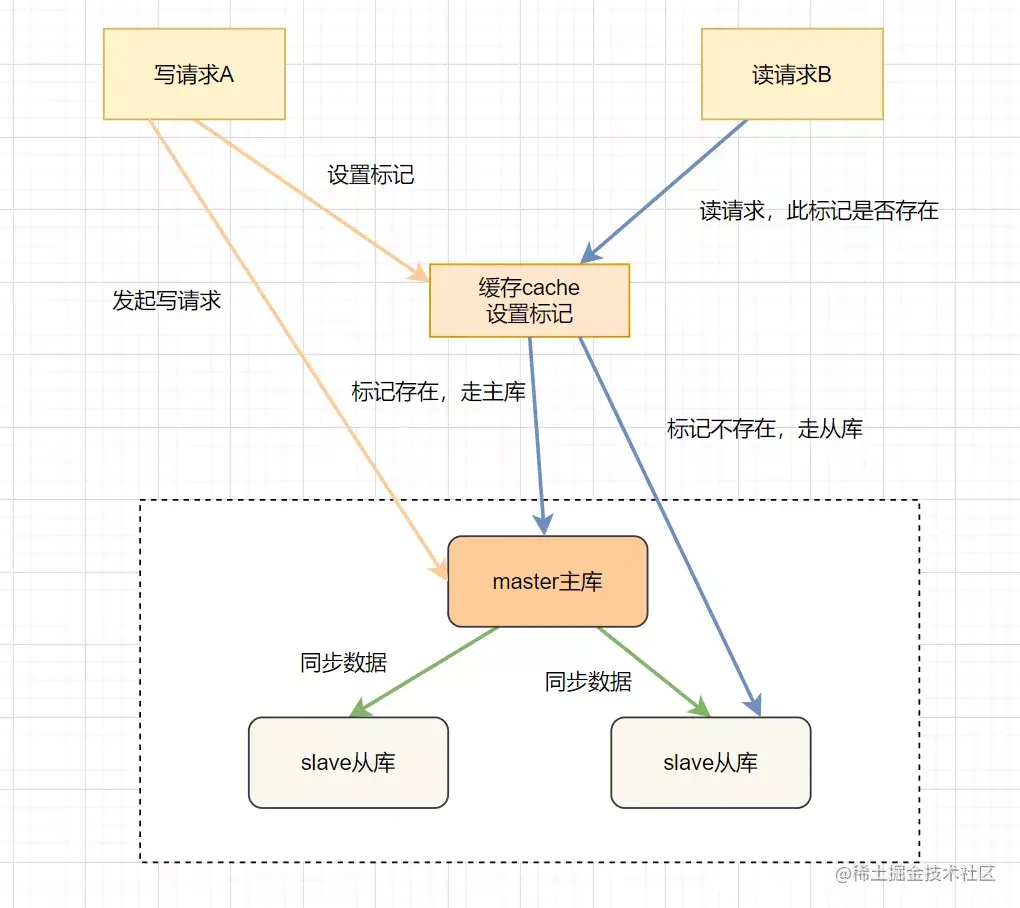
这个方案,解决了数据不一致问题,但是每次请求都要先跟缓存打交道,会影响系统吞吐。


