

为不同的业务表选择不同的存储引擎,例如:查询操作多的业务表,用 MyISAM。临时数据用 Memeroy。常规的并发大更新多的表用 InnoDB。
原则:使用可以正确存储数据的最小数据类型。
为每一列选择合适的字段类型。
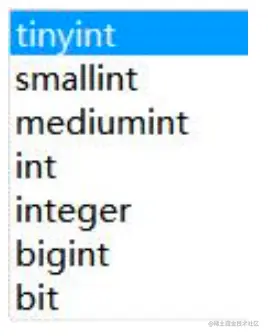
INT 有 8 种类型,不同的类型的最大存储范围是不一样的。
性别?用 TINYINT,因为 ENUM 也是整数存储。
变长情况下,varchar 更节省空间,但是对于 varchar 字段,需要一个字节来记录长度。
固定长度的用 char,不要用 varchar。
降低了可读性;
影响数据库性能,应该把计算的事情交给程序,数据库专心做存储;
数据的完整性应该在程序中检查。
不要用数据库存储图片(比如 base64 编码)或者大文件;
把文件放在 NAS 上,数据库只需要存储 URI(相对路径),在应用中配置 NAS 服务器地址。
将不常用的字段拆分出去,避免列数过多和数据量过大。
比如在业务系统中,要记录所有接收和发送的消息,这个消息是 XML 格式的,用blob 或者 text 存储,用来追踪和判断重复,可以建立一张表专门用来存储报文。
所以,如果在面试的时候再问到这个问题“你会从哪些维度来优化数据库”,你会怎么回答?

除了对于代码、SQL 语句、表定义、架构、配置优化之外,业务层面的优化也不能忽视。举两个例子:
1)在某一年的双十一,为什么会做一个充值到余额宝和余额有奖金的活动,例如充300 送 50?
因为使用余额或者余额宝付款是记录本地或者内部数据库,而使用银行卡付款,需要调用接口,操作内部数据库肯定更快。
2)在去年的双十一,为什么在凌晨禁止查询今天之外的账单?这是一种降级措施,用来保证当前最核心的业务。
3)最近几年的双十一,为什么提前个把星期就已经有双十一当天的价格了?预售分流。
在应用层面同样有很多其他的方案来优化,达到尽量减轻数据库的压力的目的,比如限流,或者引入 MQ 削峰,等等等等。
为什么同样用 MySQL,有的公司可以抗住百万千万级别的并发,而有的公司几百个并发都扛不住,关键在于怎么用。所以,用数据库慢,不代表数据库本身慢,有的时候还要往上层去优化。
当然,如果关系型数据库解决不了的问题,我们可能需要用到搜索引擎或者大数据的方案了,并不是所有的数据都要放到关系型数据库存储。
一、分析查询基本情况
1、涉及到表结构,字段的索引情况、每张表的数据量、查询的业务含义。
这个非常重要,因为有的时候你会发现 SQL 根本没必要这么写,或者表设计是有问题的。
二、找出慢的原因
1、查看执行计划,分析 SQL 的执行情况,了解表访问顺序、访问类型、索引、扫描行数等信息。
2、如果总体的时间很长,不确定哪一个因素影响最大,通过条件的增减,顺序的调整,找出引起查询慢的主要原因,不断地尝试验证。
找到原因:比如是没有走索引引起的,还是关联查询引起的,还是 order by 引起的。
找到原因之后:
三、对症下药
1、创建索引或者联合索引
2、改写 SQL,这里需要平时积累经验,例如:
1)使用小表驱动大表
3)not exist 转换为 left join IS NULL
4) or 改成 union
4)使用 UNION ALL 代替 UNION,如果结果集允许重复的话
5)大偏移的 limit,先过滤再排序。
如果 SQL 本身解决不了了,就要上升到表结构和架构了。
3、表结构(冗余、拆分、not null 等)、架构优化。
4、业务层的优化,必须条件是否必要。
如果没有思路,调优就是抓瞎,肯定没有任何头绪。


