 科技公元 后端
2023-06-06
科技公元 后端
2023-06-06
要想成为一名优秀的后端程序员,编写出高性能的服务接口是一个重要指标,高标准程序员都是对性能反复压榨的。以下梳理了一些提升接口性能的技术方案,希望对大家有所帮助。
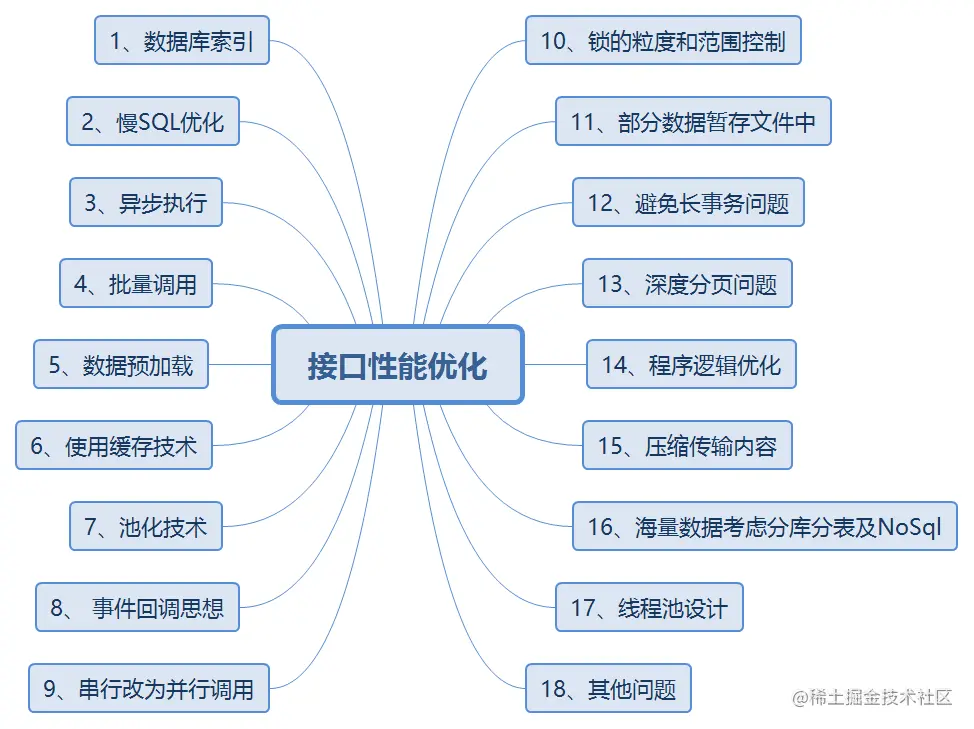
当接口出现性能问题时,最容易想到的就是添加索引,索引优化是代价最小的优化,而且效果很明显。索引优化主要从一下几个角度考虑:
SQL是否添加索引? 索引是否生效? 索引设计是否合理?
在开发阶段就要考虑数据库表的索引设计,对于一些经常作为检索条件、order by、group by 后面的字段,且数据区分度高的字段,可以考虑创建索引。
开发阶段就把创建索引脚本写好放在上线待执行脚本文件中,避免上线时忘记索引创建。
可以通过explain执行查询计划,查看SQL执行情况:
sql复制代码explain select * from user where name like '%张';
也可以通过命令show create table user,检查整张表的索引情况。
sql复制代码show create table user
如果某个表忘记添加某个索引,可以通过alter table add index命令添加索引。
sql复制代码alter table user add index idx_name (name);
注意:在数据量很大的表中创建索引,最好选择在业务不繁忙时间段,避免影响线上业务。
有时候虽然添加了索引,但是索引可能会失效,如下图梳理了索引失效的14种情况:
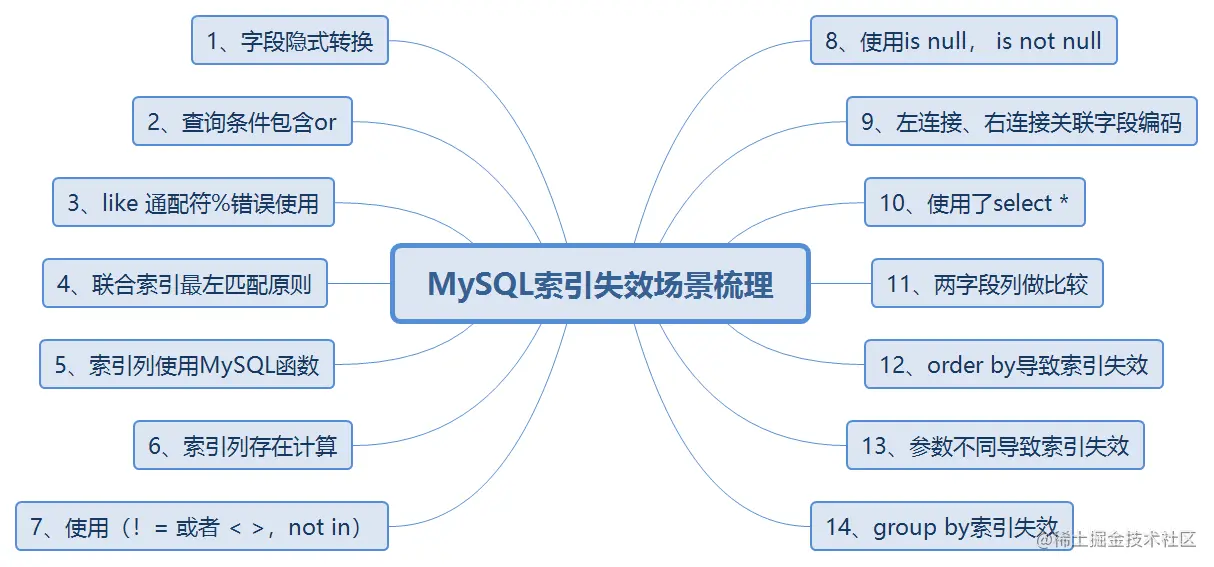 (www.bilibili.com/video/BV1yN…
(www.bilibili.com/video/BV1yN…
索引不是设计越多越好,设计必需要合理,例如:
优先考虑设计联合索引,适当使用覆盖索引; 索引个数尽量不要超过5个; 索引最好选择数据区分度较高的字段,如性别太多重复字段就不适合创建索引;
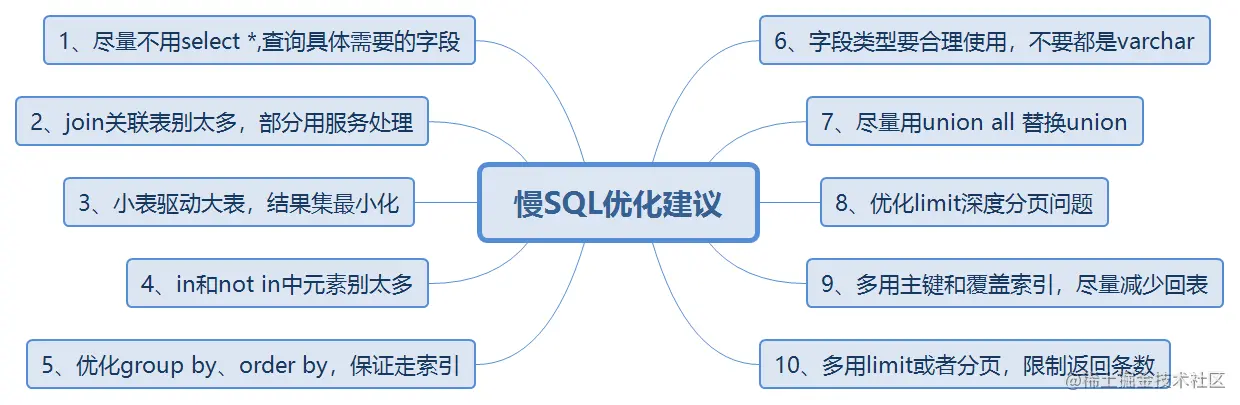
在索引优化之后,还可以进一步优化慢SQL语句,如下梳理10条慢sql优化建议:
对于一些耗时操作或者不影响主要业务的逻辑,可以采用异步执行,来提升性能。
开始
用户注册
短信发送
日志写入
积分赠送
结束
为了降低接口耗时,及时返回结果,可以把短信发送、日志写入及积分赠送通过异步执行。
类似的场景还有:用户下订单之后的消息发送及赠送积分也可以放到异步处理。
常见的异步实现:线程池、消息队列MQ、Spring注解@Async、异步框架CompletableFuture、Spring ApplicationEvent事件。
数据库操作或或者远程调用时,能批量操作就不要for循环调用。
java复制代码//反例
for(int i=0;i<n;i++){
singleUpdate(param)
}
//正例
batchUpdate(param);
打个比喻:
复制代码假如你需要搬一万块砖到一个地方,你有一辆汽车,汽车一次可以放适量的砖(最多放800), 你可以选择一次运送一块砖,也可以一次运送800,你觉得哪种方式更方便,时间消耗更少?
数据预加载策略,顾名思义就是提前把部分要用到的数据,初始化到缓存。如果你在未来某个时间需要用到某个经过复杂计算的数据,才实时去计算的话,可能耗时比较大。这时候,我们可以采取预取思想,提前把可能需要的数据计算好,放到缓存中,等需要的时候,去缓存取就行。这将大幅度提高接口性能。
场景举例:
项目启动执行方法:
java复制代码public class DataInitUtil implements ApplicationRunner{
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println("在项目启动时,会执行这个方法中的代码");
}
}
typescript复制代码@Component
public class ApplicationListenerImpl implements ApplicationListener<ApplicationStartedEvent> {
@Override
public void onApplicationEvent(ApplicationStartedEvent event) {
System.out.println("listener");
}
}
**总结:**注解方式@PostConstruct 始终最先执行
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。缓存其实就是一种空间换时间的思想,就是你把要查的数据,提前放好到缓存里面,需要时,直接查缓存,而避免去查数据库或者计算的过程。
这里的缓存包括:Redis缓存,JVM本地缓存,memcached,或者Map等等。我举个我工作中,一次使用缓存优化的设计吧,比较简单,但是思路很有借鉴的意义。 场景举例:
开始
根据用户账号
查询基本信息
进行首页展示
结束
这里用户的基本信息包含积分、期望工作地等很多信息,首页需要根据这些信息,个性化展示数据;如果每次都去查询,比较费时,可以考虑将数据缓存到redis,提高性能。
池化技术最常见的是线程池应用:
假设我们设计一个APP首页的接口,它需要查用户获奖经历、需要查资格证书、需要查岗位信息等等。那你是一个一个接口串行调,还是并行调用呢?
可以使用CompletableFuture 并行调用提高性能,类似也可以使用多线程处理。
perl复制代码// 查询获奖经历
LambdaQueryWrapper<RewardExp> rewardExpQuery = new LambdaQueryWrapper<RewardExp>()
.eq(RewardExp::getResumeId, resume.getId())
.eq(RewardExp::getDelFlag, NORMAL)
.orderByDesc(RewardExp::getDate);
CompletableFuture<List<RewardExp>> rewardExpFuture = CompletableFuture.supplyAsync(() ->
rewardExpMapper.selectList(rewardExpQuery)
);
// 查询资格证书
LambdaQueryWrapper<Credential> credentialQuery = new LambdaQueryWrapper<Credential>()
.eq(Credential::getResumeId, resume.getId())
.eq(Credential::getDelFlag, NORMAL)
.orderByDesc(Credential::getDate);
CompletableFuture<List<Credential>> credentialFuture = CompletableFuture.supplyAsync(() ->
credentialMapper.selectList(credentialQuery)
);
// 查询岗位信息
LambdaQueryWrapper<ResumeJobs> jobsQuery = new LambdaQueryWrapper<ResumeJobs>()
.eq(ResumeJobs::getResumeId, resume.getId()).eq(ResumeJobs::getDelFlag, NORMAL);
CompletableFuture<List<ResumeJobs>> jobsFuture = CompletableFuture.supplyAsync(() ->
resumeJobsMapper.selectList(jobsQuery)
);
CompletableFuture.allOf(rewardExpFuture, credentialFuture, jobsFuture).join();
在高并发场景,为了防止超卖等情况,我们经常需要加锁来保护共享资源。但是,如果加锁的粒度过粗,是很影响接口性能的。 什么是加锁粒度呢?举一个生活中的示例: 例如:你在家里上卫生间,你只需要把卫生间锁住,而不用把家里的每个房间都锁住。 无论是使用synchronized加锁还是redis分布式锁,只需要在共享临界资源加锁即可,不涉及共享资源的,就不必要加锁。 如下示例代码,只是方法A涉及共享资源操作,就只需要锁住A方法就好; 很多小伙伴容易一锅端,全锁住,如果锁住的代码耗时,其实是比较影响性能的。 错误:
scss复制代码void wrongMethod(){
synchronized (this) {
doMethodB();
A();
}
}
正确:
scss复制代码void rightMethod(){
doMethodB();
synchronized (this) {
A();
}
}
如果接口耗时瓶颈就在数据库插入操作这里,用批量操作等策略,效果还不理想,就可以考虑用文件或者消息队列、redis等暂存。有时候批量数据放到文件,会比插入数据库效率更高。 该策略的主要思想:就是在大数据量时,将业务数据写入文件中,再通过异步的方式去消费文件中的数据,执行对应的业务逻辑,减少数据库DB的瞬时压力。
场景举例:
开始
调用三方接口
获取季度考勤明细
数据汇总
数据存储
结束
由于季度考勤数据量很大,逐个接收处理汇总很费时,可以采用将数据按15天分组写入到一个文件中,然后异步去消费文件中数据进行汇总处理。
如何避免长事务问题:
如何解决长事务问题:
scss复制代码@Transactional
public int createUser(User user){
//保存用户信息
userDao.save(user);
passCertDao.updateFlag(user.getPassId());
// 该方法为远程RPC接口
sendEmailRpc(user.getEmail());
return user.getUserId();
}
直接使用@Transactional 注解,Spring的声明式事务,整个方法都在事务中,而且里面存在远程RPC调用,容易出现长事务问题。
数据库的深度分页问题,比较影响接口性能,如下所示SQL语句:
bash复制代码select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
limit 100000,10意味着会扫描100010行,丢弃掉前100000行,最后返回10行。即使create_time,也会回表很多次。 可以通过标签记录法和延迟关联法来优化深分页问题。 1. 标签记录法 就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
bash复制代码select id,name,balance FROM account where id > 100000 limit 10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了id主键索引。但是这种方式有局限性:需要一种类似连续自增的字段,而且需要前端把上次最大值传给后端。
2. 延迟关联法 延迟关联法,就是把条件转移到主键索引树,然后减少回表。优化后的SQL如下:
sql复制代码select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;
优化思路就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
优化程序逻辑、程序代码,是可以节省耗时的。比如,你的程序创建多不必要的对象、或者程序逻辑混乱,多次重复查数据库、又或者你的实现逻辑算法不是最高效的等等。 常见思路:通过使用visiol建模工具或者其他方法,梳理清楚代码逻辑,检查是否存在不必要的对象创建、逻辑调用或者代码细节之类的,是否符合一些编码规范。
因为文件太大传入会比较消耗网络带宽资源,进一步影响到服务接口的耗时消耗。例如后端需要返回图片到前端加载,该优化策略可以找UI在不影响图片清晰度的前提下,对图片进行适当压缩,节省网络带宽,提高接口性能。
如果确实是因为数据量太大导致的性能问题,可以考虑使用分库分表策略,包括垂直拆分和水平拆分,在程序查询sql中性能得到提升。 同时也可以考虑ElasticSearch,对大数据查询都有很好的性能支持。 场景举例: 之前有个业务需求,需要查询用户报表数据,报表数据包括用户维度的很多属性信息,用户表数据量很大,查询时需要join很多表,如果用关系型数据库存在严重性能问题,如下图所示
开始
查询用户表
查询积分表
查询订单
查询发票
查询实名信息等
结束
**解决方案:**通过XxlJob定时任务,在晚上业务不繁忙时,将用户报表数据离线生成好,并存放到ElasticSearch中,界面上展示时后端直接通过Es查询,提高了查询接口性能。
我们使用线程池,就是让任务并行处理,更高效地完成任务。但是有时候,如果线程池设计不合理,接口执行效率则不太理想。
一般我们需要关注线程池的这几个参数:核心线程、最大线程数量、阻塞队列。
普通接口
消息推送
写入日志
核心接口
首页加载
登录接口
线程池隔离
解决服务接口性能问题,是程序员进阶的必经之路。 总的来说性能优化通用方法是:从用户发起请求的整个链路分析,将分隔相关环节加上log日志,打印环节耗时,找到接口性能问题出现位置,再结合以上介绍的优化方案进行处理。


