
————————————————
版权声明:本文为 简书 博主「_code_x」的原创文章。
原文链接:https://www.jianshu.com/p/95952167a260
rpc解决了什么问题
简单的说:
最终解决的问题:让分布式或者微服务系统中不同服务之间的调用(远程调用)像本地调用一样简单!调用者感知不到远程调用的逻辑。为此rpc需要解决三个问题(实现的关键):
Call ID映射。我们怎么告诉远程机器(注册中心)我们要调用哪个函数呢?
在本地调用中,函数体是直接通过函数指针来指定的,我们调用具体函数,编译器就自动帮我们调用它相应的函数指针。
但是在远程调用中,是无法调用函数指针的,因为两个进程的地址空间是完全不一样。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个 {函数 <--> Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
序列化和反序列化。客户端怎么把参数值传给远程的函数呢?
在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。
但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
数据网络传输。远程调用往往是基于网络的,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。
网络传输层需要把Call ID和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分RPC框架都使用TCP协议,但其实UDP也可以,而gRPC干脆就用了HTTP2。Java的Netty(基于NIO通信方式作为高性能网络服务的前提)也属于这层的东西。
RPC调用流程:
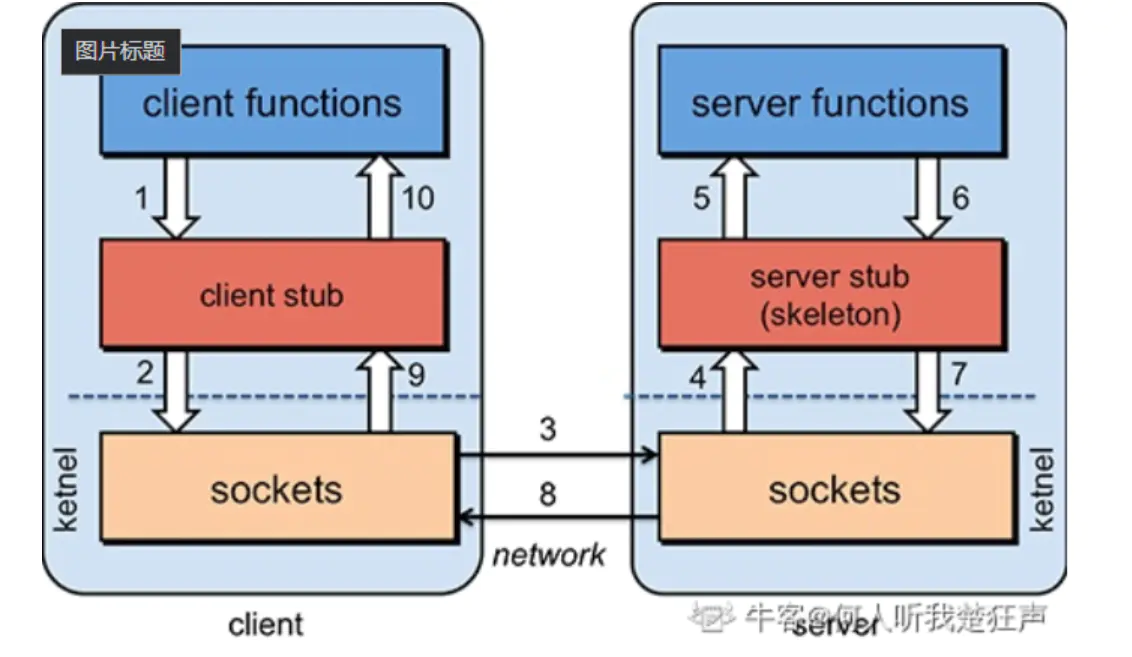
一个完整的RPC架构里面包含了四个核心的组件,分别是Client ,Server,Client Stub以及Server Stub,这个Stub大家可以理解为存根(调用与返回)。分别说说这几个组件:
小结:RPC 的目标就是封装调用过程,用户无需关心这些细节,可以像调用本地方法一样即可完成远程服务调用。
要实现一个RPC不算难,难的是实现一个高性能、高可靠、高可用的RPC框架(需要考虑的问题)
常用的RPC框架
数据交互为什么用 RPC,不用 HTTP?
除 RPC 之外,常见的多系统数据交互方案还有分布式消息队列、HTTP 请求调用、数据库和分布式缓存等。RPC 和 HTTP 调用是没有经过中间件的,它们是端到端系统的直接数据交互。
首先需要指正,这两个并不是并行概念。RPC 是一种设计,就是为了解决不同服务之间的调用问题,完整的 RPC 实现一般会包含有 传输协议 和 序列化协议 这两个。
而 HTTP 是一种传输协议,RPC 框架完全可以使用 HTTP 作为传输协议,也可以直接使用 TCP,使用不同的协议一般也是为了适应不同的场景使用 TCP 和使用 HTTP 各有优势:
(1)传输效率:
(2)性能消耗,主要在于序列化和反序列化的耗时
(3)跨平台:
总结:
调用如何实现客户端无感(动态代理技术)? 与静态代理的区别。
静态代理:每个代理类只能为一个接口服务,这样会产生很多代理类。普通代理模式,代理类Proxy的Java代码在JVM运行时就已经确定了,也就是静态代理在编码编译阶段就确定了Proxy类的代码。而动态代理是指在JVM运行过程中,动态的创建一个类的代理类,并实例化代理对象。
JDK 动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用业务方法前调用InvocationHandler 处理。代理类必须实现 InvocationHandler 接口,并且,JDK 动态代理只能代理实现了接口的类。
JDK 动态代理类基本步骤,如果想代理没有实现接口的对象?
JDK 动态代理类基本步骤:
InvocationHandler 接口,重写 invoke() 方法;Proxy.newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)动态创建代理类对象,通过代理类对象调用业务方法。CGLIB 框架实现了对无接口的对象进行代理的方式。JDK 动态代理是基于接口实现的,而 CGLIB 是基于继承实现的。它会对目标类产生一个代理子类,通过方法拦截技术过滤父类的方法调用。代理子类需要实现 MethodInterceptor 接口。
CGLIB 底层是通过 asm 字节码框架实时生成类的字节码,达到动态创建类的目的,效率较 JDK 动态代理低。Spring 中的 AOP 就是基于动态代理的,如果被代理类实现了某个接口,Spring 会采用 JDK 动态代理,否则会采用 CGLIB。
写一个动态代理的例子
利用Java的反射技术(Java Reflection),在运行时创建一个实现某些给定接口的新类(也称“动态代理类”)及其实例(对象),代理的是接口(Interfaces),不是类(Class),也不是抽象类。在运行时才知道具体的实现,spring aop就是此原理。
// 1、创建代理对象的接口
interface DemoInterface {
String hello(String msg);
}
// 2、创建具体被代理对象的实现类
class DemoImpl implements DemoInterface {
@Override
public String hello(String msg) {
System.out.println("msg = " + msg);
return "hello";
}
}
// 3、创建一个InvocationHandler实现类,持有被代理对象的引用,invoke方法中:利用反射调用被代理对象的方法
class DemoProxy implements InvocationHandler {
private DemoInterface service;
public DemoProxy(DemoInterface service) {
this.service = service;
}
@Override
public Object invoke(Object obj, Method method, Object[] args) throws Throwable {
System.out.println("调用方法前...");
Object returnValue = method.invoke(service, args);
System.out.println("调用方法后...");
return returnValue;
}
}
public class Solution {
public static void main(String[] args) {
DemoProxy proxy = new DemoProxy(new DemoImpl());
//4.使用Proxy.newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)动态创建代理类对象,通过代理类对象调用业务方法。
DemoInterface service = (DemoInterface)Proxy.newProxyInstance(
DemoInterface.class.getClassLoader(),
new Class<?>[]{DemoInterface.class},
proxy
);
System.out.println(service.hello("呀哈喽!"));
}
}
输出:
调用方法前...
msg = 呀哈喽!
调用方法后...
hello
拓展:
newProxyInstance:
invoke三个参数:
对象是怎么在网络中传输的?
通过将对象序列化成字节数组,即可将对象发送到网络中。在 Java 中,想要序列化一个对象:
Serializable 接口;序列化对象主要由两种用途:
把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中或数据库中;
比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些session先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
用于网络传输对象的字节序列。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
在 Java 序列化期间,哪些变量未序列化?
序列化期间,静态变量(static修饰)和瞬态变量(transient修饰)未被序列化:
如果有一个属性(字段)不想被序列化的,则该属性必须被声明为 transient!
如何实现对象的序列化和反序列化?
将需要序列化的类实现Serializable接口就可以了,Serializable接口中没有任何方法,可以理解为一个标记,即表明这个类可以序列化。JDK 中提供了 ObjectOutStream 类来对对象进行序列化。对象序列化(将对象转化为字节序列)包括如下步骤:
ObjectOutputStream out = new ObjectOutputStream(new fileOutputStream(“D:\\objectfile.obj”));
out.writeObject(“Hello”);
对象的反序列化(将字节序列重建成一个对象的过程)步骤如下:
ObjectInputStream in = new ObjectINputStream(new fileInputStream(“D:\\objectfile.obj”));
String obj1 = (String)in.readObject();
区别可外部接口:
Externalizable 给我们提供 writeExternal() 和 readExternal() 方法, 这让我们灵活地控制 Java 序列化机制, 而不是依赖于 Java 的默认序列化。正确实现 Externalizable 接口可以显著提高应用程序的性能。
框架中实现了哪几种序列化方式,介绍一下?
实现了 JSON、Kryo、Hessian 和 Protobuf 的序列化。后三种都是基于字节的序列化。
serialVersionUID的作用
Java的序列化机制是通过 在运行时 判断类的serialVersionUID来验证版本一致性的(用于实现对象的版本控制)。
serialVersionUID 是一个 private static final long 型 ID, 当它被印在对象上时, 它通常是对象的哈希码,你可以使用 serialver 这个 JDK 工具来查看序列化对象的 serialVersionUID。
在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。(InvalidCastException)
类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的 serialVersionUID,也有可能相同。为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
显式地定义serialVersionUID有两种用途:
在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
简单介绍Netty
Netty概述:
特点和优势:
为什么Netty性质高?
简单说一下IO模型,BIO、NIO与AIO
Java的IO阻塞和非阻塞以及同步和异步的问题:
(1)BIO(同步阻塞):
传统BIO,一个连接一个线程,客户端有连接请求时服务器端就需要启动一个线程进行处理。线程开销大。数据的读写必须阻塞在一个线程内,等待其完成。
伪异步IO:将请求连接放入线程池,一对多,但线程还是很宝贵的资源,但底层还是同步阻塞IO。具体是将客户端的Socket请求封装成一个task任务(实现Runnable类)然后投递到线程池中去,配置相应的队列实现。
存在的问题:在读取数据较慢时(比如数据量大、网络传输慢等),大量并发的情况下,其他接入的消息,只能一直等待,这就是最大的弊端。这就是阻塞IO存在的弊端,对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性。
(2)NIO(同步非阻塞):
(3)AIO(异步非阻塞):
一个有效请求一个线程,客户端的I/O请求都是由OS先完成了,再通知服务器应用去启动线程进行处理。
在NIO编程之上引入了异步通道的概念,并提供了异步文件和异步套接字的实现,从而真正实现了异步非阻塞。AIO它不需要通过多路复用器对注册的通道进行轮询操作即可以实现异步读写,从而简化了NIO编程模型。
适用于连接数目多且连接比较长(重操作)的架构,充分调用OS参与并发操作,编程比较复杂;而 NIO方式适用于连接数目多且连接比较短(轻操作)的架构,并发局限于应用中。
Netty线性模型?
Netty 通过 Reactor 模型基于多路复用器接收并处理用户请求,内部实现了两个线程池, boss 线程池和 worker 线程池,其中 boss 线程池的线程负责处理请求的 accept 事件,当接收到 accept 事件的请求时,把对应的 socket 封装到一个 NioSocketChannel 中,并交给 worker 线程池,其中 worker 线程池负责请求的 read 和 write 事件,由对应的Handler 处理。
如何解决 TCP 的粘包拆包问题
TCP 是以流的方式来处理数据,一个完整的包可能会被 TCP 拆分成多个包进行发送;也可能把小的封装成一个大的数据包发送(多个小的数据包合并发送),对于接收端的应用程序拿到缓冲区的数据不知如何拆分。
TCP 粘包/拆包的原因:应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象,而应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上(将发送端的缓冲区填满一次性发送),这将会发生粘包现象;总之:出现TCP 粘包/拆包的关键:套接字缓冲区大小限制与应用程序写入数据大小的关系。
Netty 自带解决方式,Netty对解决粘包和拆包的方案做了抽象,提供了一些解码器(Decoder)来解决粘包和拆包的问题。如:
消息定长:FixedLengthFrameDecoder 类
包尾增加特殊字符分割:
将消息分为消息头和消息体:LengthFieldBasedFrameDecoder 类。适用于消息头包含消息长度的协议(最常用)。
分为有头部的拆包与粘包、长度字段在前且有头部的拆包与粘包、多扩展头部的拆包与粘包。
基于Netty进行网络读写的程序,可以直接使用这些Decoder来完成数据包的解码。对于高并发、大流量的系统来说,每个数据包都不应该传输多余的数据(所以补齐的方式不可取),LenghtFieldBasedFrameDecode更适合这样的场景。
常见的解决方案:
说下 Netty 零拷贝
Netty 的零拷贝主要包含三个方面:
说下 Netty 重要组件
核心组件:
Bytebuf(字节容器):网络通信最终都是通过字节流进行传输的。 ByteBuf 就是 Netty 提供的一个字节容器,其内部是一个字节数组。 当我们通过 Netty 传输数据的时候,就是通过 ByteBuf 进行的。可以将ByteBuf看作是 Netty 对 Java NIO 提供了 ByteBuffer字节容器(复杂和繁琐)的封装和抽象。
Bootstrap 和 ServerBootstrap(启动引导类):
Channel接口(Netty 网络操作抽象类):可以进行基本的 I/O 操作,如 bind、connect、read、write 等。 一旦客户端成功连接服务端,就会新建一个Channel同该用户端进行绑定。常见的实现类:
NioServerSocketChannel(服务端)NioSocketChannel(客户端)这两个 Channel 可以和 BIO 编程模型中的ServerSocket以及Socket两个概念对应上。
EventLoop接口(事件循环):主要是配合 Channel 处理 I/O 操作,用来处理连接的生命周期中所发生的事情。 实际就是负责监听网络事件并调用事件处理器进行相关 I/O 操作(读写)的处理。

sync()方法将其变为同步。与用户逻辑与数据流密切相关:
ChannelHandler 被添加到的 ChannelPipeline 它得到一个 ChannelHandlerContext。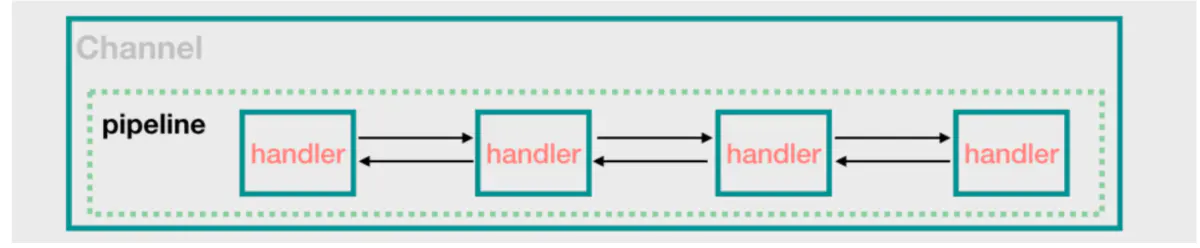
Netty 是如何保持长连接的(心跳机制)
首先 TCP 协议的实现中也提供了 keepalive 报文用来探测对端是否可用。TCP 层将在定时时间到后发送相应的 KeepAlive 探针以确定连接可用性。打开该设置:
ChannelOption.SO_KEEPALIVE, true
TCP 心跳的问题:
考虑一种情况,某台服务器因为某些原因导致负载超高,CPU 100%,无法响应任何业务请求,但是使用 TCP 探针则仍旧能够确定连接状态,这就是典型的连接活着但业务提供方已死的状态,对客户端而言,这时的最好选择就是断线后重新连接其他服务器,而不是一直认为当前服务器是可用状态一直向当前服务器发送些必然会失败的请求。
Netty 中提供了 IdleStateHandler 类专门用于处理心跳。IdleStateHandler 的构造函数如下:
public IdleStateHandler(long readerIdleTime, long writerIdleTime,
long allIdleTime,TimeUnit unit){
}
channelRead() 方法超过 readerIdleTime 时间未被调用则会触发超时事件调用 userEventTrigger() 方法;write() 方法超过 writerIdleTime 时间未被调用则会触发超时事件调用 userEventTrigger() 方法;所以这里可以分别控制读,写,读写超时的时间,单位为秒,如果是0表示不检测,所以如果全是0,则相当于没添加这个 IdleStateHandler,连接是个普通的短连接。
待补充。。。
责任链模式与在netty中的应用
适用场景:对于一个请求来说,如果有个对象都有机会处理它,而且不明确到底是哪个对象会处理请求时,我们可以考虑使用责任链模式实现它,让请求从链的头部往后移动,直到链上的一个节点成功处理了它为止
优点:
缺点:
所有的请求都从链的头部开始遍历,对性能有损耗
极差的情况,不保证请求一定会被处理
巨人的肩膀:
https://www.nowcoder.com/discuss/588903?channel=-1&source_id=profile_follow_post_nctrack
https://www.jianshu.com/p/28e48e5f9c73
https://blog.csdn.net/qq_21125183/article/details/86161620
https://andyoung.blog.csdn.net/article/details/113632855
https://www.cnblogs.com/ZhuChangwu/p/11241304.html
作者:_code_x
链接:https://www.jianshu.com/p/95952167a260
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


