 宅哥聊构架 工具
2022-07-29
宅哥聊构架 工具
2022-07-29
当您面对成吨的会议录音,着急写会议纪要而不得不愚公移山、人海战术?听的头晕眼花,听的漏洞百出,听的怀疑人生,那么你是否想到了自动听写服务?
想想也是,百度一看,好家伙,收费不菲啊!请看下图
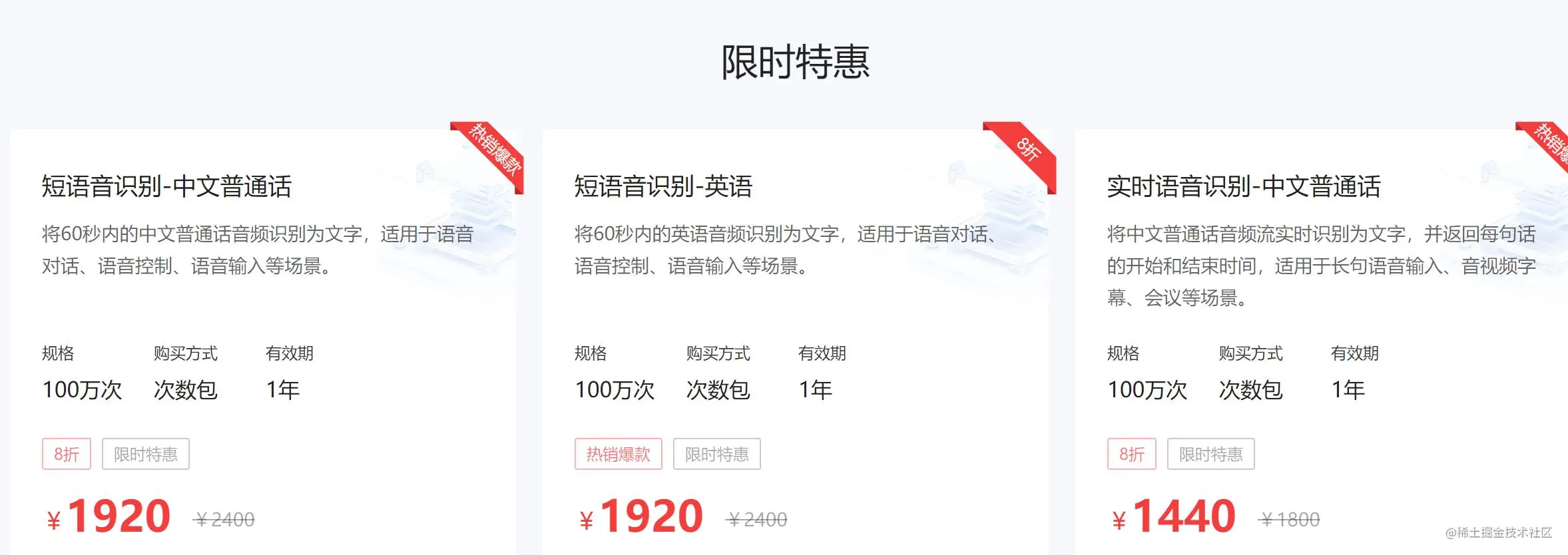

亲密,能花钱解决的都不是事,刚刚看到听写服务,很贵的,大致1400大洋,还是打折完毕的,而且还是云服务形式的,那么对于某些会议,比如保密会议,需要离线的,那么完全办不到,该怎么办呢?下面就有请我们的PaddleSpeech出场来解决问题。
【超简单】之基于PaddleSpeech搭建个人语音听写服务,顾名思义,是通过PaddleSpeech来搭建语音听写服务的,主要思路如下。
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用如下:
pip install paddlespeech
复制代码1.win必须安装 Microsoft C++ 生成工具 - Visual Studiovisualstudio.microsoft.com/zh-hans/vis… 工具,原因是 安装非纯 Python 包或编译 Cython 或 Pyrex 文件。
2.参考: WindowsCompilers - Python Wikiwiki.python.org/moin/Window…
!pip install paddlespeech >log.log
复制代码!wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
复制代码--2022-07-27 00:31:57-- https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
Resolving paddlespeech.bj.bcebos.com (paddlespeech.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a
Connecting to paddlespeech.bj.bcebos.com (paddlespeech.bj.bcebos.com)|182.61.200.195|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 159942 (156K) [audio/wav]
Saving to: ‘zh.wav’
zh.wav 100%[===================>] 156.19K --.-KB/s in 0.03s
2022-07-27 00:31:57 (5.52 MB/s) - ‘zh.wav’ saved [159942/159942]
复制代码from paddlespeech.cli.asr.infer import ASRExecutor
asr = ASRExecutor()
result = asr(audio_file="zh.wav")
复制代码[2022-07-27 00:33:02,175] [ INFO] - checking the audio file format......
复制代码print(result)
复制代码我认为跑步最重要的就是给我带来了身体健康
复制代码!paddlespeech asr --lang zh --input zh.wav
复制代码/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/nltk/decorators.py:68: DeprecationWarning: `formatargspec` is deprecated since Python 3.5. Use `signature` and the `Signature` object directly
regargs, varargs, varkwargs, defaults, formatvalue=lambda value: ""
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/nltk/lm/counter.py:15: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sequence, defaultdict
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/nltk/lm/vocabulary.py:13: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Counter, Iterable
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /home/aistudio/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to /home/aistudio/nltk_data...
[nltk_data] Unzipping corpora/cmudict.zip.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
W0727 00:38:55.935500 2181 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0727 00:38:55.940197 2181 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/h5py/__init__.py:36: DeprecationWarning: `np.typeDict` is a deprecated alias for `np.sctypeDict`.
from ._conv import register_converters as _register_converters
我认为跑步最重要的就是给我带来了身体健康
复制代码会自动下载一堆东西有点慢,可以不用这个。
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /home/aistudio/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to /home/aistudio/nltk_data...
复制代码如遇到以下错误
[2022-07-26 21:13:28,589] [ INFO] - checking the audio file format......
[2022-07-26 21:13:28,594] [ ERROR] - Please input audio file less then 50 seconds.
复制代码报错很明显,提示一个是音频格式问题,一个是小于50s问题,如果遇到这个问题后面解决。
1.音频必须为wav格式
2.音频大小必须小于50s
音频格式为wav格式,这个可通过录音笔设置(一般默认),或python代码转换,或者格式工厂进行转换。
此处使用auditok库
!pip install auditok
复制代码Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting auditok
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/49/3a/8b5579063cfb7ae3e89d40d495f4eff6e9cdefa14096ec0654d6aac52617/auditok-0.2.0-py3-none-any.whl (1.5 MB)
l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.5 MB ? eta -:--:--━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.4/1.5 MB 14.2 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━ 1.3/1.5 MB 19.7 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.5/1.5 MB 15.4 MB/s eta 0:00:00
[?25hInstalling collected packages: auditok
Successfully installed auditok-0.2.0
[notice] A new release of pip available: 22.1.2 -> 22.2
[notice] To update, run: pip install --upgrade pip
复制代码切分原因上面交代过,因为PaddleSpeech识别最长语音为50s,故需要切分,这里直接调用好了。
from paddlespeech.cli.asr.infer import ASRExecutor
import csv
import moviepy.editor as mp
import auditok
import os
import paddle
from paddlespeech.cli import ASRExecutor, TextExecutor
import soundfile
import librosa
import warnings
warnings.filterwarnings('ignore')
复制代码# 引入auditok库
import auditok
# 输入类别为audio
def qiefen(path, ty='audio', mmin_dur=1, mmax_dur=100000, mmax_silence=1, menergy_threshold=55):
audio_file = path
audio, audio_sample_rate = soundfile.read(
audio_file, dtype="int16", always_2d=True)
audio_regions = auditok.split(
audio_file,
min_dur=mmin_dur, # minimum duration of a valid audio event in seconds
max_dur=mmax_dur, # maximum duration of an event
# maximum duration of tolerated continuous silence within an event
max_silence=mmax_silence,
energy_threshold=menergy_threshold # threshold of detection
)
for i, r in enumerate(audio_regions):
# Regions returned by `split` have 'start' and 'end' metadata fields
print(
"Region {i}: {r.meta.start:.3f}s -- {r.meta.end:.3f}s".format(i=i, r=r))
epath = ''
file_pre = str(epath.join(audio_file.split('.')[0].split('/')[-1]))
mk = 'change'
if (os.path.exists(mk) == False):
os.mkdir(mk)
if (os.path.exists(mk + '/' + ty) == False):
os.mkdir(mk + '/' + ty)
if (os.path.exists(mk + '/' + ty + '/' + file_pre) == False):
os.mkdir(mk + '/' + ty + '/' + file_pre)
num = i
# 为了取前三位数字排序
s = '000000' + str(num)
file_save = mk + '/' + ty + '/' + file_pre + '/' + \
s[-3:] + '-' + '{meta.start:.3f}-{meta.end:.3f}' + '.wav'
filename = r.save(file_save)
print("region saved as: {}".format(filename))
return mk + '/' + ty + '/' + file_pre

