 程序浅谈 后端
2024-09-30
程序浅谈 后端
2024-09-30

本文主要讲述了“栈”数据结构的特性,以及 golang 如何实现栈,并拓展了一些可以使用栈结构解决的算法题。
栈是一种 FILO 类型(FILO 即 Fisrt In Last Out)的数据结构,也就是先进后出,也可以说是后进先出。
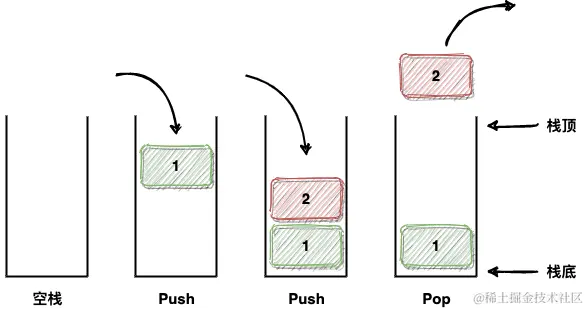
栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的,所以栈不是容器,而是容器适配器。
栈主要方法为 push 和 pop,不支持迭代器功能(不支持遍历元素),提供查看栈内元素数量、栈顶元素的方法,接下来让我们使用 golang 语言实现一下栈吧。
本小节分别使用 slice 和 链表结构实现栈,并通过 golang benchmark 简单测试一下性能。
特点:
代码解读复制代码package stack
import (
"sync"
)
// Item 栈中存储的数据类型,这里使用接口
type Item interface{}
// ItemStack 存储 Item 类型的栈
type ItemStack struct {
items []Item
lock sync.RWMutex
}
// NewStack 创建 ItemStack
func NewStack() *ItemStack {
s := &ItemStack{}
s.items = []Item{}
return s
}
// Push 入栈
func (s *ItemStack) Push(t Item) {
s.lock.Lock()
s.lock.Unlock()
s.items = append(s.items, t)
}
// Pop 出栈
func (s *ItemStack) Pop() Item {
s.lock.Lock()
defer s.lock.Unlock()
if s.Len() == 0 {
return nil
}
item := s.items[s.Len()-1]
s.items = s.items[0 : s.Len()-1]
return item
}
// Len 栈内存储的元素数量
func (s *ItemStack) Len() int {
return len(s.items)
}
// Peek 查看栈顶元素
func (s *ItemStack) Peek() interface{} {
if s.Len() == 0 {
return nil
}
return s.items[s.Len()-1]
}
针对 slice 实现的基准测试go
代码解读复制代码package stack
import (
"testing"
)
var stack *ItemStack
func init() {
stack = NewSliceStack()
}
func Benchmark_Push(b *testing.B) {
for i := 0; i < b.N; i++ {
stack.Push("test")
}
}
func Benchmark_Pop(b *testing.B) {
b.StopTimer()
for i := 0; i < b.N; i++ {
stack.Push("test")
}
b.StartTimer()
for i := 0; i < b.N; i++ {
stack.Pop()
}
}
测试结果:go
代码解读复制代码go test -test.bench=".*" -benchmem
goos: darwin
goarch: amd64
pkg: data_structure/stack
cpu: Intel(R) Core(TM) i5-1038NG7 CPU @ 2.00GHz
Benchmark_Push
Benchmark_Push-8 13897054 73.70 ns/op 86 B/op 0 allocs/op
Benchmark_Pop
Benchmark_Pop-8 38605101 28.74 ns/op 0 B/op 0 allocs/op
PASS
ok data_structure/stack 6.269s
特点:
代码解读复制代码package stack
import (
"sync"
)
type (
Stack struct {
top *node
length int
lock *sync.RWMutex
}
node struct {
value interface{}
prev *node
}
)
func NewListStack() *Stack {
return &Stack{nil, 0, &sync.RWMutex{}}
}
func (s *Stack) Len() int {
return s.length
}
func (s *Stack) Peek() interface{} {
if s.length == 0 {
return nil
}
return s.top.value
}
func (s *Stack) Pop() interface{} {
s.lock.Lock()
defer s.lock.Unlock()
if s.length == 0 {
return nil
}
n := s.top
s.top = n.prev
s.length--
return n.value
}
func (s *Stack) Push(value interface{}) {
s.lock.Lock()
defer s.lock.Unlock()
n := &node{value, s.top}
s.top = n
s.length++
}
针对链表实现的基准测试go
代码解读复制代码package stack
import (
"testing"
)
var stack *Stack
func init() {
stack = NewListStack()
}
func Benchmark_Push(b *testing.B) {
for i := 0; i < b.N; i++ {
stack.Push("test")
}
}
func Benchmark_Pop(b *testing.B) {
b.StopTimer()
for i := 0; i < b.N; i++ {
stack.Push("test")
}
b.StartTimer()
for i := 0; i < b.N; i++ {
stack.Pop()
}
}
测试结果:go
代码解读复制代码stack go test -test.bench=".*" -benchmem
goos: darwin
goarch: amd64
pkg: data_structure/stack
cpu: Intel(R) Core(TM) i5-1038NG7 CPU @ 2.00GHz
Benchmark_Push
Benchmark_Push-8 12294496 86.13 ns/op 24 B/op 1 allocs/op
Benchmark_Pop
Benchmark_Pop-8 41718554 36.03 ns/op 0 B/op 0 allocs/op
PASS
ok data_structure/stack 8.449s
golang benchmark 参数以及结果简单介绍:
测试分别执行了 5 次,数据基本偏差不大,可以确定结论
基于 slice 的栈执行速度更快
基于 slice 的栈内存占用的更多(数据太少的情况不算在内)
| 栈的实现方式 | push 速度 | push 内存分配 | pop 速度 |
|---|---|---|---|
| 基于 slice | 73.70 ns/op | 86 B/op | 28.74 ns/op |
| 基于 链表 | 86.13 ns/op | 24 B/op | 36.03 ns/op |
由于栈结构的特殊性,非常适合做对称匹配类的题目。
leetcode 原题: 有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。有效字符串需满足:
示例 1:输入:s = "()" 输出:true
示例 2:输入:s = "()[]{}" 输出:true
示例 3:输入:s = "(]" 输出:false
提示:
解题思路:
这是一个对称匹配的问题:
代码解读复制代码func isValid(s string) bool {
// 匹配项
hash := map[byte]byte{
'}': '{',
']': '[',
')': '(',
}
stack := make([]byte, 0)
for i := 0; i < len(s); i++ {
if s[i] == '{' || s[i] == '[' || s[i] == '(' {
// 左括号
stack = append(stack, s[i])
} else {
if len(stack) > 0 && stack[len(stack)-1] == hash[s[i]] {
// 除左括号外就是有括号(题目提示)
stack = stack[:len(stack)-1]
} else {
// 右括号没匹配上,不符合要求
return false
}
}
}
return len(stack) == 0
}
leetcode 原题:删除字符串中所有相邻重复项
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。在 S 上反复执行重复项删除操作,直到无法继续删除。在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:输入:"abbaca" 输出:"ca" 解释: 例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
提示:
解题思路:
类似上题,这是个匹配消除问题,也是需要找到对称匹配,进行消除。
代码解读复制代码func removeDuplicates(s string) string {
stack := make([]byte, 0)
for i := 0; i < len(s); i++ {
if len(stack) == 0 {
stack = append(stack, s[i])
continue
}
// 和栈顶元素重复,则删除
if s[i] == stack[len(stack)-1] {
stack = stack[:len(stack)-1]
} else {
stack = append(stack, s[i])
}
}
return string(stack)
}
leetcode 原题:括号的分数
给定一个平衡括号字符串 S,按下述规则计算该字符串的分数:
示例 1:
输入: "()" 输出: 1
示例 2:
输入: "(())" 输出: 2
示例 3:
输入: "()()" 输出: 2
示例 4:
输入: "(()(()))" 输出: 6
提示:
解题思路:
看到括号匹配,就会想到用栈解决,但这道题按以往的思路尝试解决似乎不太容易,如果只是把括号入栈,则无法记录消除匹配括号产生的中间值,因此变得难以下手。但换种思路想一想,我们利用栈记录平衡括号字符串的分数,利用栈结构对中间值进行计算,最终栈顶元素则为最终结果,问题迎刃而解。
通过观察我们可以发现,()结构贡献了分数,外括号为该结构添加了乘数,同层括号之间以加法计算,计算平衡括号字符串 s 分数的过程可以拆解为计算平衡括号字符串子串的过程,可能的结果有两种:
通过栈结构,可以先把不能计算的部分入栈,将可计算的子串计算出来后,合并为更大的子串,通过出栈的方式,把之前入栈的部分继续计算,一步步计算更大的子串,最终 s 为自身最大的子串,计算结束。
可以把 s 看作是一个空字符串加上 s 本身,并且定义空字符串的分数为 0。使用栈记录平衡字符串的分数,在开始之前要压入分数 0,表示空字符串的分数。
在遍历字符串 s 的过程中:
遍历结束后,栈顶元素保存的就是 s 的分数。go
代码解读复制代码func scoreOfParentheses(s string) int {
// 栈顶元素表示子串得分
// 压 0 入栈,表示空字符串的得分
// s = "" + s
st := []int{0}
for _, v := range s {
// 左括号:压 0 入栈(表示空字符串的得分),表示本括号对开始
if v == '(' {
st = append(st, 0)
continue
}
// 右括号表示本括号对结束:计算子串分数
// 1. 出栈(子串得分)
item := st[len(st)-1]
st = st[:len(st)-1]
// 2. 栈顶元素为 0,说明子串 =()得分为1
if item == 0 {
item = 1
} else {
// 栈顶不为 0,说明子串 = (A), 得分为 2 * A
item = 2 * item
}
// 子串计算完毕后与栈顶元素(前一个子串)相加,成为更大的子串
st[len(st)-1] = st[len(st)-1] + item
}
// 栈顶元素为最终得分,最终 len(st)-1 = 0
return st[len(st)-1]
}

