 科技公元 后端
2023-05-04
科技公元 后端
2023-05-04
所谓缓存,实际上是借助高速存储介质来提升读性能的一种技术。从工程角度来看,缓存可以分为本地缓存和分布式缓存,本地缓存一般由静态变量来承载,其可以实现类间共享与进程内共享,但无法做到进程间共享,而分布式缓则可以实现进程间共享的,分布式缓存常常由 Redis 来承载。
引入分布式缓存不仅可以显著提升查询性能与吞吐量,还可以为数据库屏蔽大流量的冲击,但技术往往是一把双刃剑,在享受分布式缓存红利的同时,它也带来了数据一致性挑战。在分布式环境下,数据库与分布式缓存之间一定会存在数据不一致的情形,我们要做的就是尽可能缩小数据不一致的时间窗口,追求最终一致性!
引入分布式缓存后,数据查询场景往往涉及缓存回填,而数据更新场景则涉及缓存更新。回填也好,更新也罢,均有可能触发数据不一致问题,但要往根儿上捋的话,缓存更新才是造成数据不一致的罪魁祸首,如果说往 Redis 回填的是旧数据,那必然是在这期间发生了缓存更新。
缓存更新一般有四种组合动作,分别是:
下面一起来分析下这四种缓存更新动作究竟是如何造成数据不一致现象的;同时也要探索出哪一种缓存更新动作最佳,数据不一致的时间窗口最小。在笔者《Redis 分布式锁的再研究》一文中曾提到 Martin Kleppmann 大佬认为 RedLock 是一种不伦不类、完全建立在三种假设 (进程暂停、网络时延、时钟漂移) 基础上的分布式锁方案,的确,进程暂停、网络时延和时钟漂移算得上是 JVM 分布式系统中的三大拦路虎了;为了更直观、清晰地描述数据不一致现象,咱们依然选用进程暂停作为分析手段,其实网络时延也具备相同的效果···
先更新 MySQL 再更新 Redis
在 先更新 MySQL 再更新 Redis 动作下,也就不涉及缓存回填了。
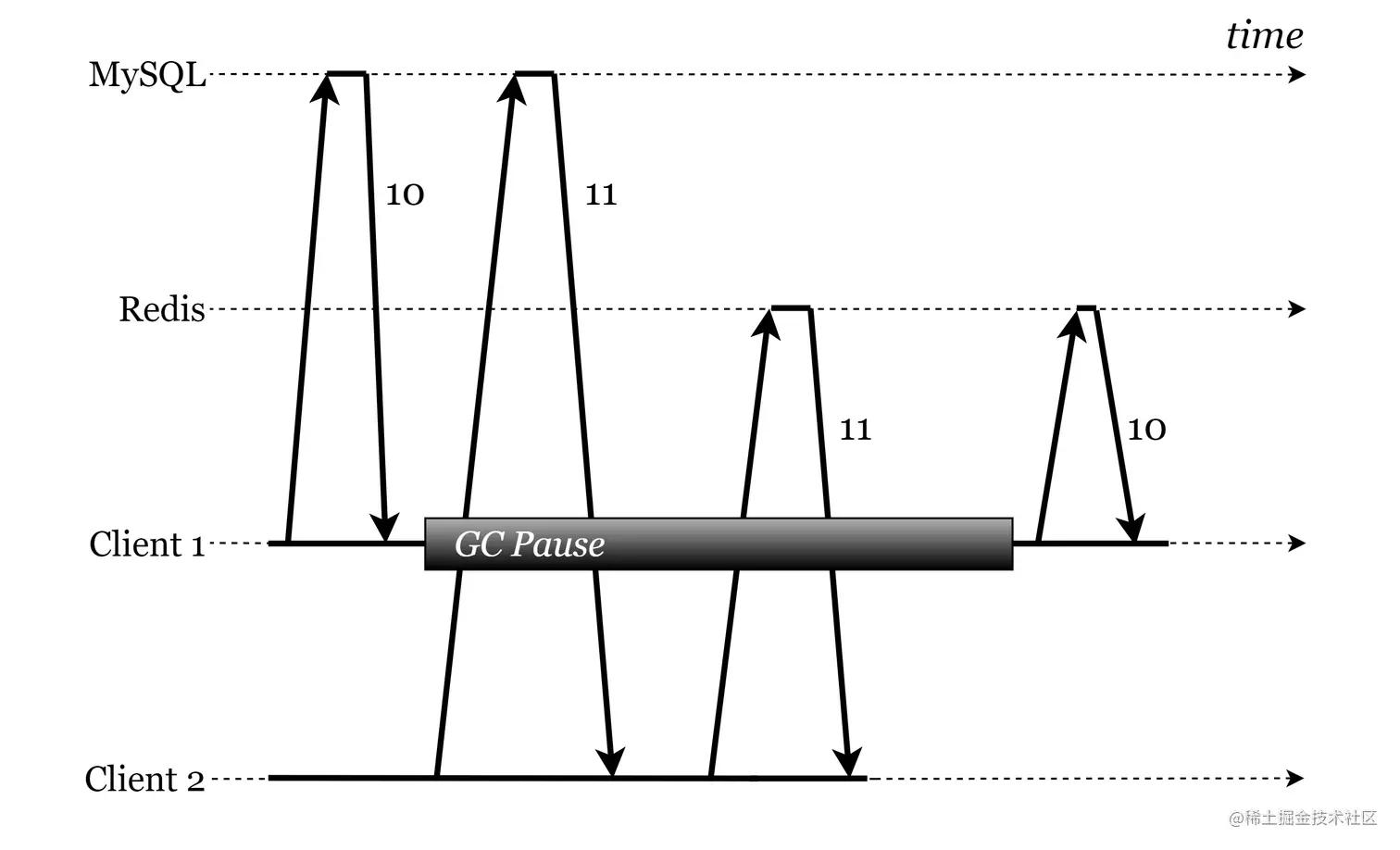
先更新 Redis 再更新 MySQL
在 先更新 Redis 再更新 MySQL 动作下,同样也不涉及缓存回填。
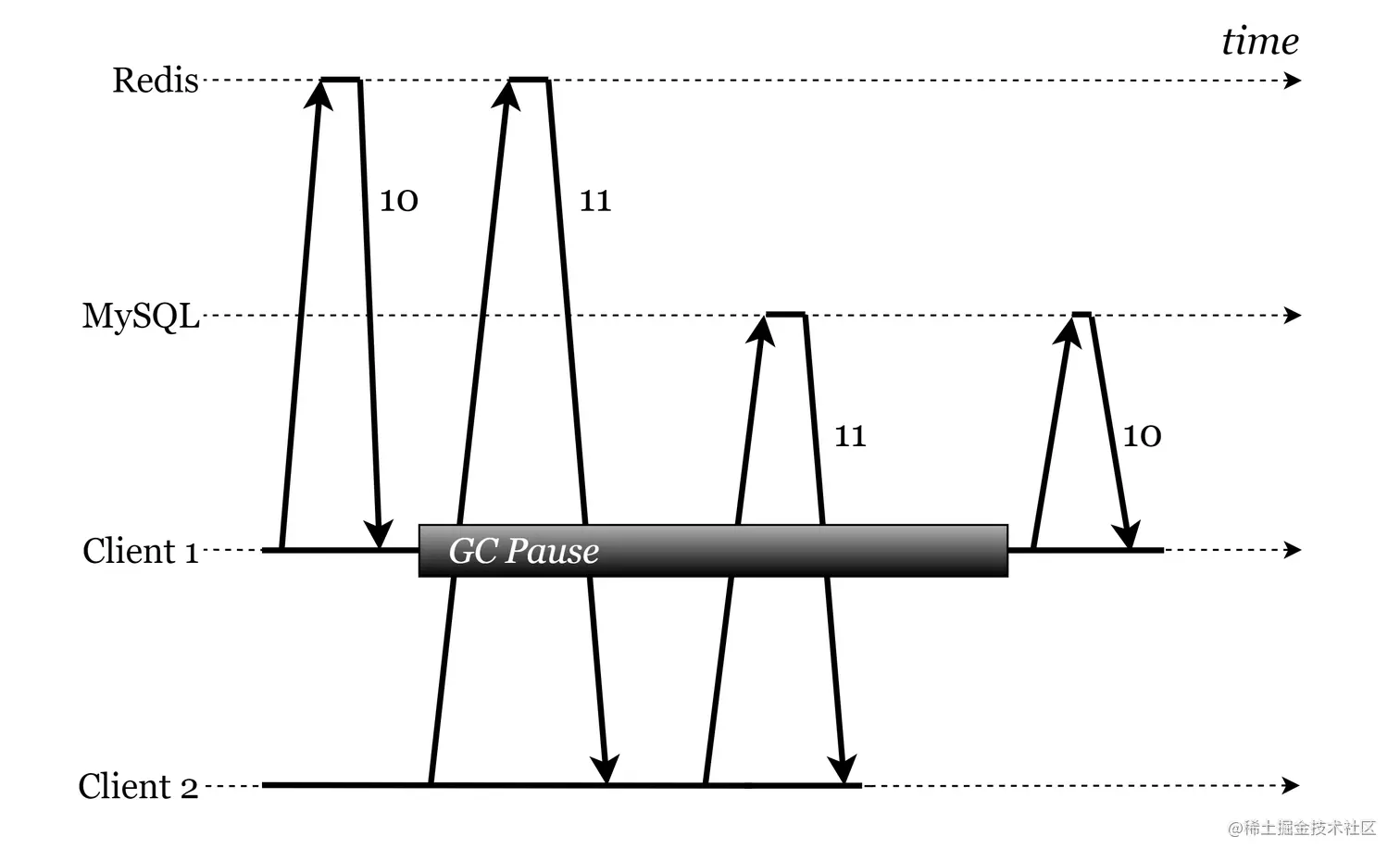
先更新 MySQL 再删除 Redis
在 先更新 MySQL 再删除 Redis 动作下,涉及缓存回填。
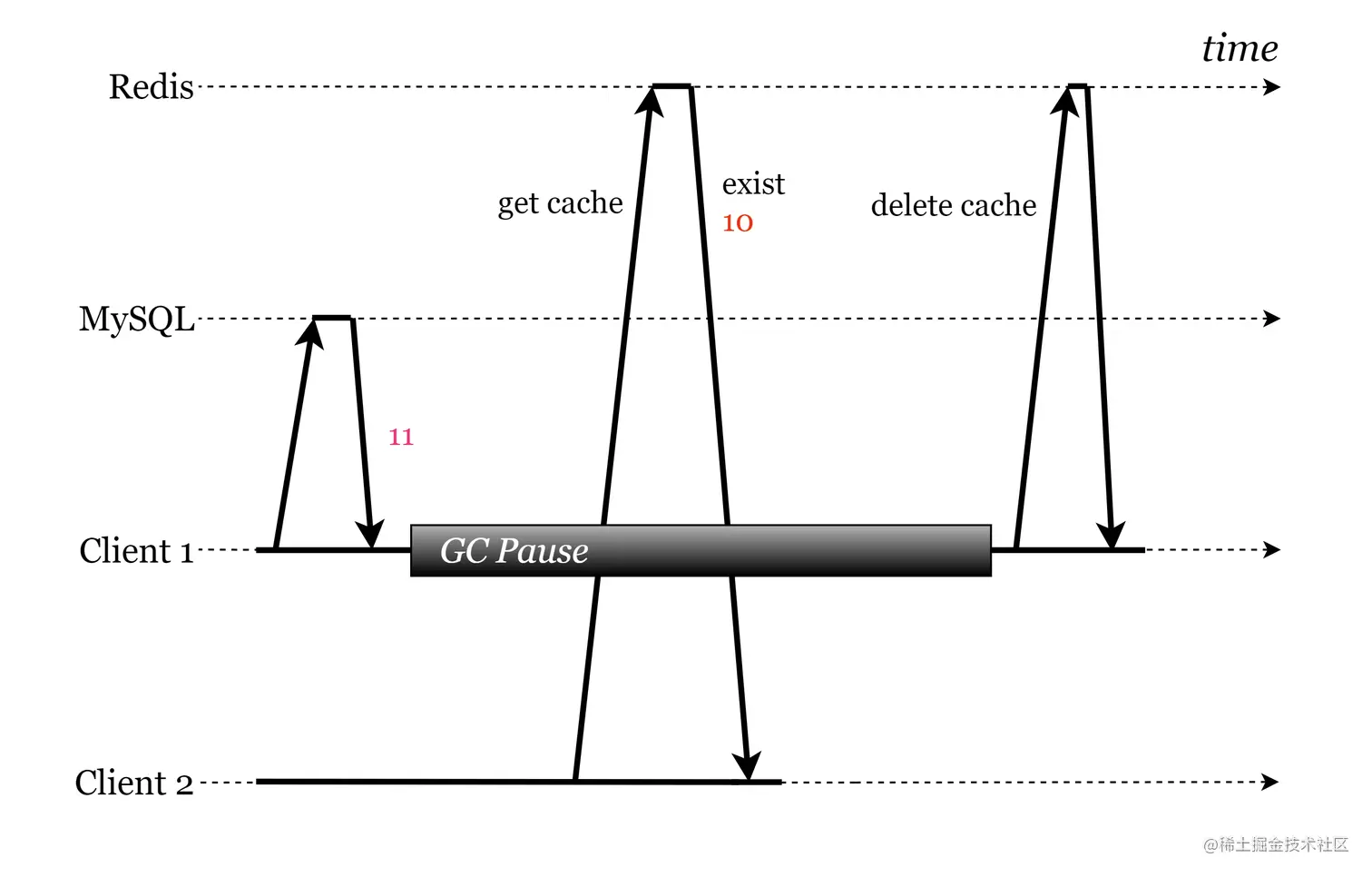
从上图来看,的确出现了数据不一致现象,但能确保达到最终一致性,这应该不算大问题,而下面这种情形可就不好了。
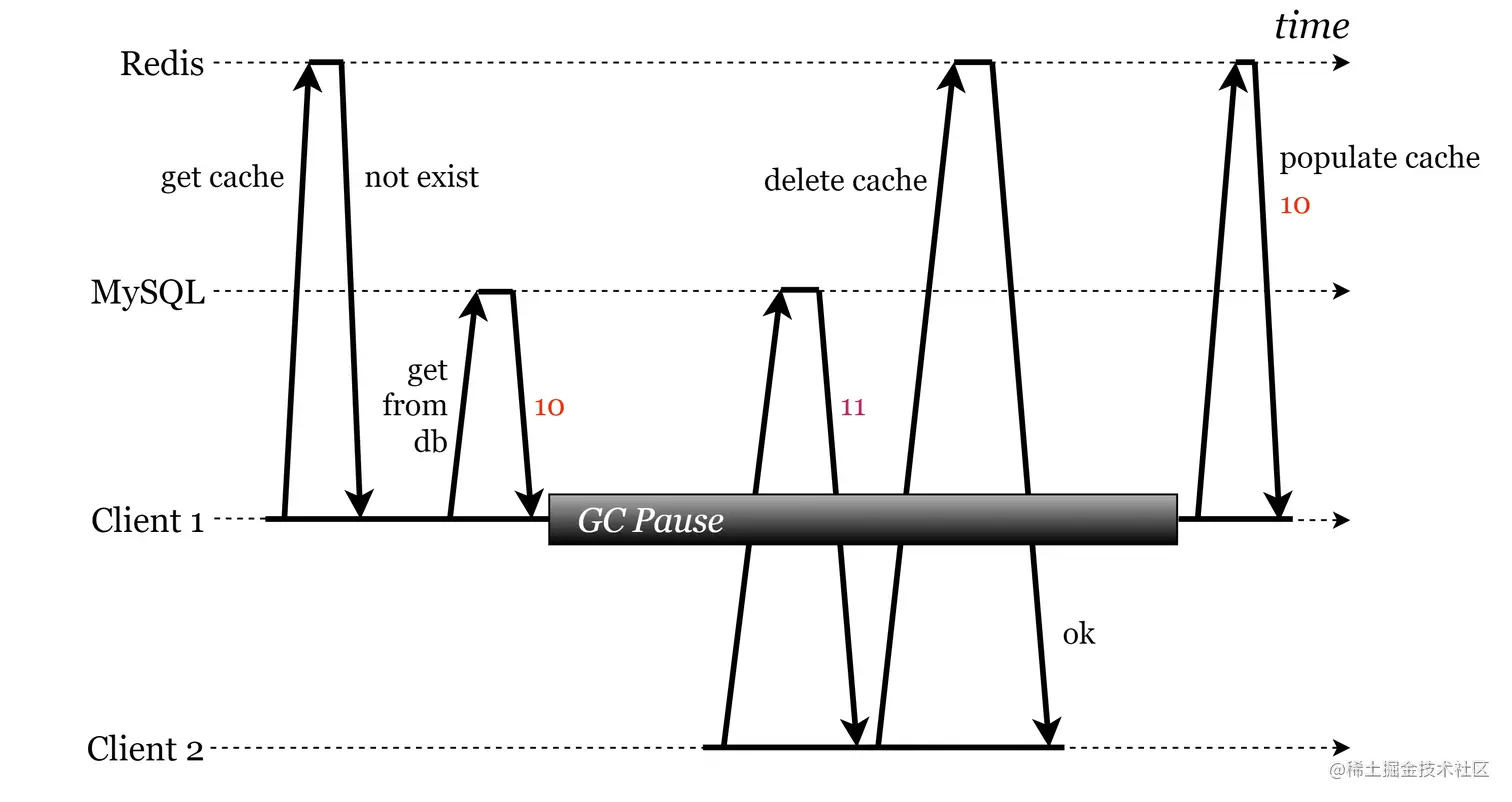
先删除 Redis 再更新 MySQL
在 先删除 Redis 再更新 MySQL 动作下,同样也涉及缓存回填。
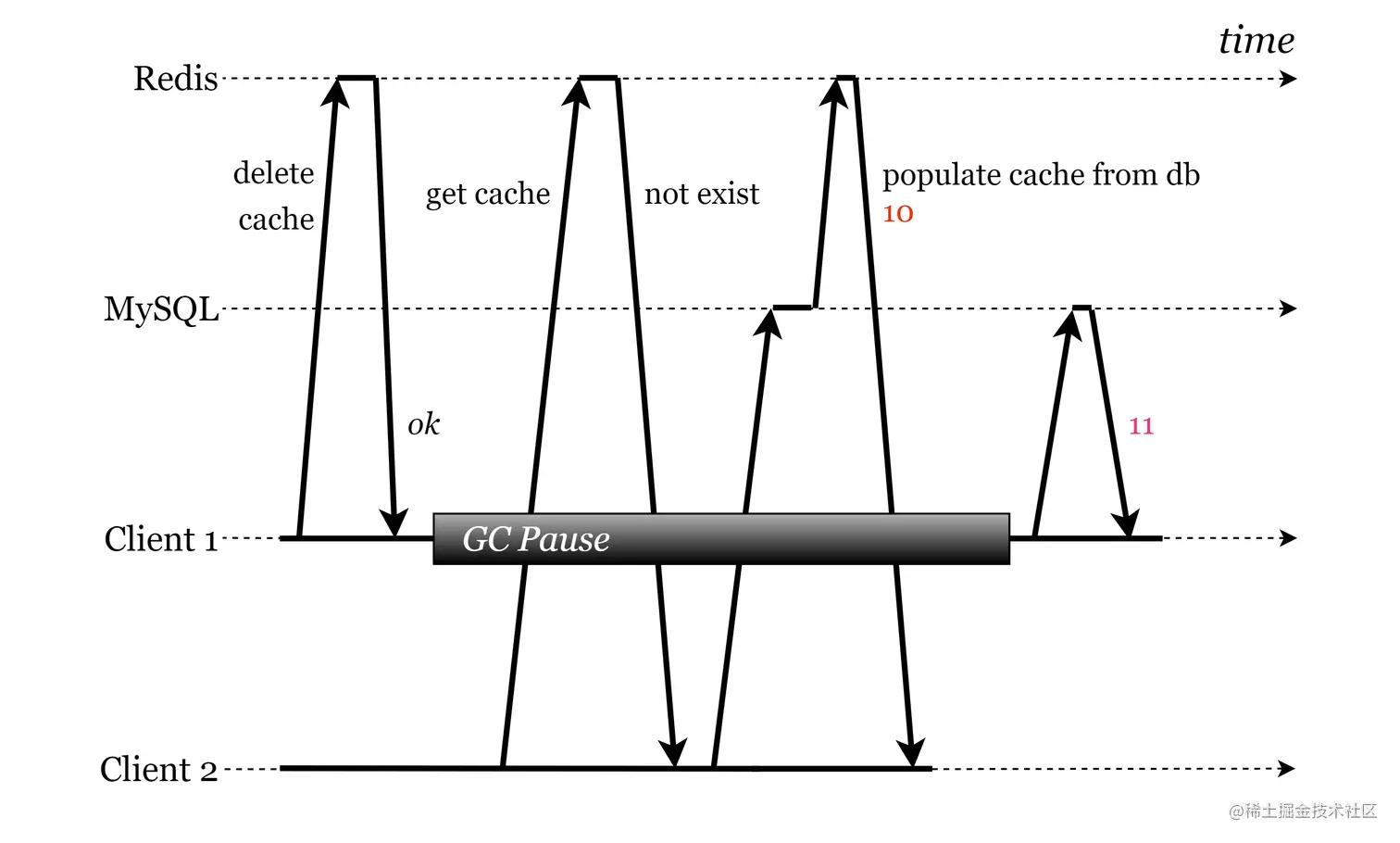
前两种缓存方案均是一种缓存更新动作,有点费力不讨好,万一缓存更新后一直没有被命中呢,大家应该避免使用。而在后两种方案中,先更新 MySQL 再删除 Redis 是要优于 先删除 Redis 再更新 MySQL 方案的,因为 数据库查询与缓存回填之间的时间窗口 往往小于 缓存删除与数据库更新之间的时间窗口,也就是说 先更新 MySQL 再删除 Redis 方案所引发数据不一致现象的概率更低。
如果业务场景并发度不高,那选用 先更新 MySQL 再删除 Redis 方案完全够了,但如果要追求更高的一致性体验,笔者觉得携程技术公众号上分享的 干货 | 分布式缓存与DB秒级一致设计实践 方案很值得我们借鉴。该方案主要核心点如下:
mod(hash(key))这一方式将同一 key 发送到 MQ 中同一队列。关于 CDC 方案本文就不介绍了,因为 CDC 方案中除了 CDC 工具之外的细节在携程方案中均有所体现。
当然,分布式缓存领域中并不只有数据一致性这一个挑战,还有缓存穿透、缓存击穿和缓存雪崩。



