前言
我们开发人员在进行并发编程时,总是会面临并发带来的安全性和一致性的挑战,为了解决这一问题,我们通常会采用同步机制和锁机制,例如Java中的synchronized关键字和Lock接口。
MySQL同样需要解决并发事务带来的复杂问题,上文简单介绍了MySQL通过事务隔离机制可以解决并发问题,本文将结合案例进行深入剖析,以便掌握其原理并学习其思想。
并发事务情况分析
如果读过之前的文章就会知道,每行数据的读写都是基于数据页操作的。那么在此基础上,并发事务可能存在以下几种情况:
- 并发事务读/读数据页中的某行数据。
- 并发事务读/写数据页中的某行数据。
- 并发事务写/写数据页中的某行数据。
如果没有并发控制的情况下,单纯的读操作是不会对数据造成什么影响。但是,一旦涉及到写操作,情况就会变得很复杂:如果此时有一个事务对某行数据进行写操作,其他事务能否对该行数据进行读取?
这个问题有以下几个情形:
- 如果可以,写事务进行回滚后,读事务的数据就不是最新状态了,一致性如何保证?
- 如果不可以,读事务是不是只能进行排队等待写事务的完成,性能如何保证?
- 如果不排队等待,又怎么保证读事务的数据是最新状态(一致性)?
各隔离级别如何处理并发事务?
到这里应该就看明白了。结合事务隔离级别:
不处理
第一个情形不就是“读未提交”的“脏读”,一致性保证不了一点。
使用锁
第二个情形就是“串行化”,完全通过锁来处理并发事务。使用锁意味着需要竞争,而竞争失败就需要等待,等待就意味着消耗时间,消耗时间就意味着会影响整体并发处理能力。
对于MySQL这样的数据库,性能的高低会直接影响用户的去留,仅仅是“串行化”并发处理是远远不够的。
MVCC
所以,为了兼顾并发事务的一致性和性能问题(也就是第三个情形),就诞生MVCC,也是隔离级别“读已提交”和“可重复读”所运用到的技术。
什么是MVCC?
MVCC 全称 Multi-Version Concurrency Control(多版本并发控制),在数据库管理系统中通过保存数据的多个版本来避免读写冲突,从而提高并发处理能力。
如何理解MVCC?
这里关注两个关键字:多版本、读写冲突。
结合上面的并发事务情况分析:
- 单纯的并发读操作不用做任何的并发处理。
- 并发写操作又避免不了锁机制。
- 并发读写如果不做控制可能会有“脏读”问题,如果使用“串行化”处理并发,又会影响整体性能。
所以只能在并发读写这里进行优化,所谓的避免读写冲突。
接下来就来看一下MVCC是如何在写事务处理的同时,保证读事务不需要排队等待就能获取到数据最新状态的。
MVCC的并发处理
数据的多版本
在《MySQL是如何保证数据不丢失的》,每个DML操作在更新数据页之前,InnoDB会先将数据当前的状态记录在「Undo Log」中。
既然这样,那么读事务直接读取这里的数据不就好了?这样的话,写事务在处理过程中,读事务既不需要排队等待,又能读取到除当前写事务之外最新的数据状态,也避免了因写事务的回滚而造成的“脏读”问题。如下图。
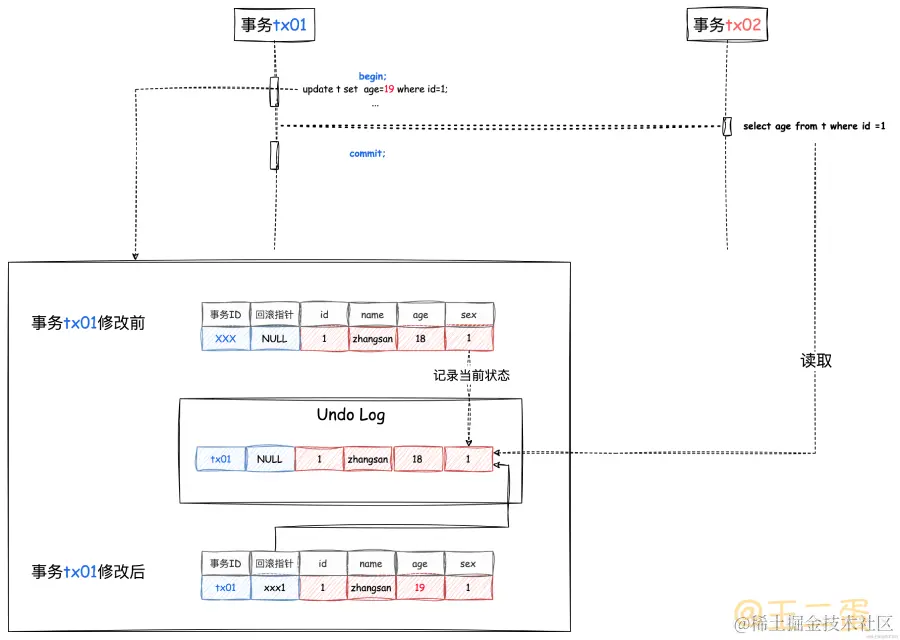
在并发事务中如果有多个写事务,那么Undo Log是这样的:
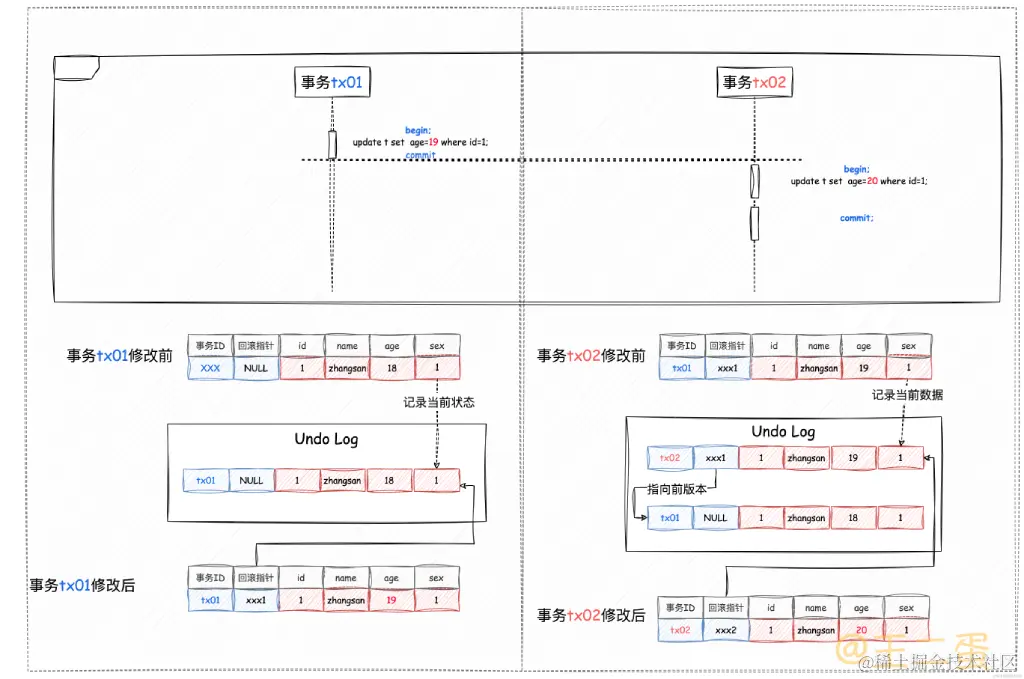
图中的「事务ID」和「回滚指针」是行数据中包含的「隐藏字段」,在 Undo Log 中通过回滚指针进行串联的数据就是指MVCC的「多版本」。
(这里说明下,同时执行DML操作时还是会使用锁来控制的,不会减少对锁的竞争。所以图中有个先后顺序。)
选择数据的某个版本
那么读事务应该以哪个版本的数据为准?
针对这个问题,MVCC通过Read View机制来处理。
Read View是什么?
Read View是事务进行读操作时生成的一个读视图,记录当前活跃事务的ID,分别是:
- trx_list:Read View生成时刻正活跃的事务ID。
- up_limit_id:trx_list列表中事务ID最小的值。
- low_limit_id:已出现过的事务ID的最大值加1。
通过Read View可以判断在当前事务能看到哪个版本的数据。
判断逻辑是这样的:
- 如果数据行记录的事务ID小于up_limit_id,表示该记录在当前事务开始之前就已经提交了,因此对当前事务是可见的。
- 如果数据行记录的事务ID大于等于up_limit_id且小于low_limit_id,表示该记录正在被写事务操作,可以读取上个已提交的版本数据。
- 如果数据行记录的事务ID大于等于low_limit_id,则该记录对当前事务不可见,因为它是在当前事务开始后产生的。
(这里说明下,事务ID是递增的。
案例说明
接下来,通过一张图具体看一下Read View怎么判断的。
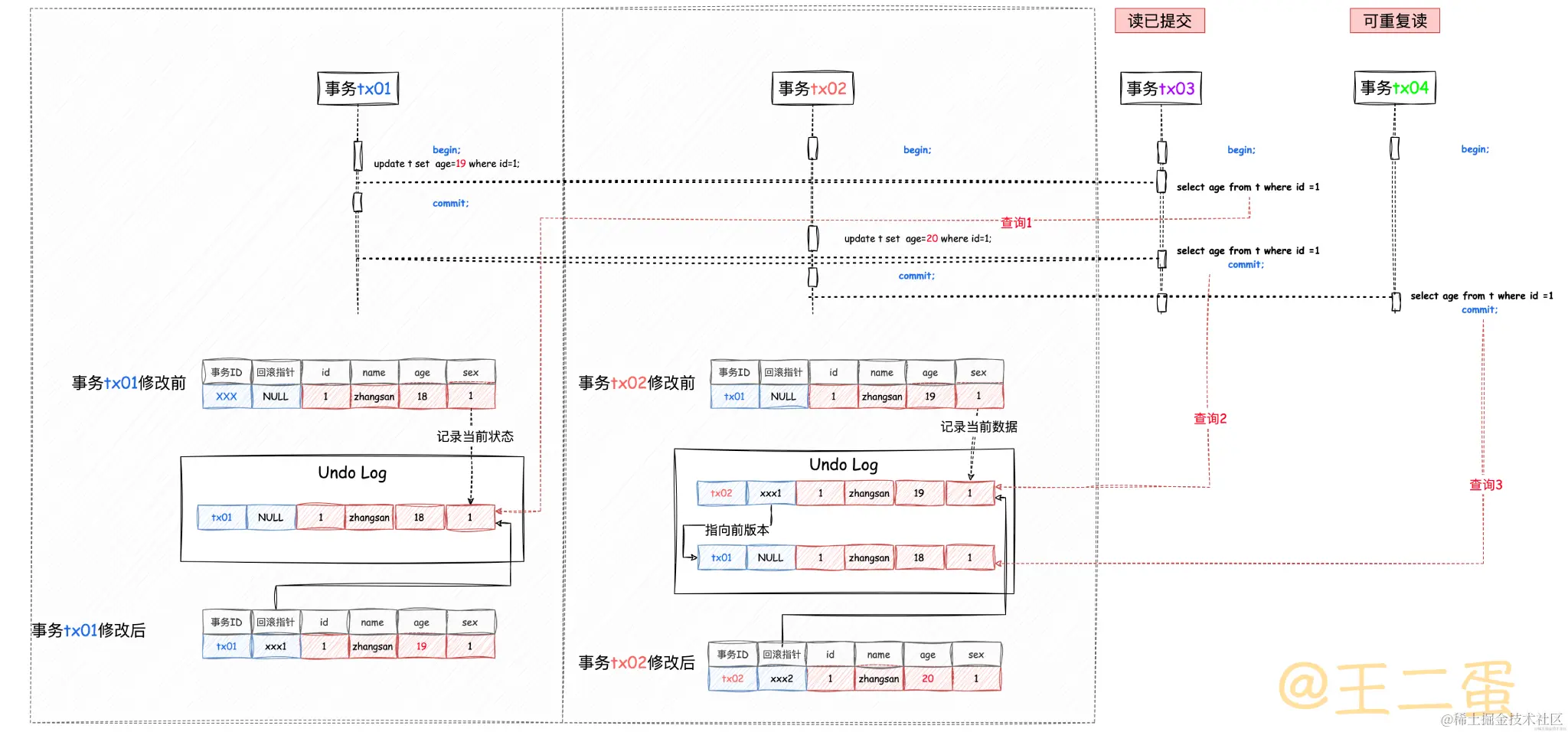
图中有4个并发事务,并且在同一时刻开启了事务。
- 查询1是事务tx03在事务tx01已修改未提交时进行查询,事务tx02的update还未开始执行,所以当前数据的事务ID=tx01,活跃的事务ID为[tx01、tx02、tx03、tx04],按照Read View的逻辑:
- tx01 不小于 up_limit_id(tx01),所以当前行记录age=19不可见。
- tx01 大于等于 up_limit_id(tx01) 且小于 low_limit_id(tx05),可以读取上个已提交(XXX)的数据,也就是age=18。
- 查询2是事务tx03在事务tx01已提交,事务tx02已修改未提交时进行查询,所以当前数据的事务ID=tx02,活跃的事务ID为[tx02、tx03、tx04],按照Read View的逻辑:
- tx02 不小于 up_limit_id(tx02),所以当前行记录age=20不可见。
- tx02 大于等于 up_limit_id(tx02) 且小于 low_limit_id(tx05),可以读取上个已提交(tx01)的数据,也就是age=19。
- 查询3是事务tx04在事务tx02已提交时进行查询,所以当前数据的事务ID=tx02,由于是可重复读,所以在事务开始就生成了活跃的事务ID[tx01、tx02、tx03、tx04],按照Read View的逻辑:
- tx02 不小于 up_limit_id(tx01),所以当前行记录age=20不可见。
- tx02 大于等于 up_limit_id(tx01) 且小于 low_limit_id(tx05),可以读取上个已提交(XXX)的数据,也就是age=18。
各位可以按照这个逻辑,自行设置场景进行代入验证。
总结
基于上述,有以下总结:
- MySQL通过事务隔离、锁机制、MVCC处理并发事务。
- 事务隔离“读未提交”不做并发处理,不保证数据一致性。
- 事务隔离“串行化”通过锁机制进行并发处理,并发性能低下。
- 事务隔离“读已提交”和“可重复读”通过MVCC进行并发处理,并发性能高。
- MVCC是通过Undo Log(多版本)结合Read View(快照)实现了无锁读并解决了一致性问题。
转载来源:https://juejin.cn/post/7346036731727511578



