 宅哥聊构架 后端
2023-01-03
宅哥聊构架 后端
2023-01-03
这几年随着转转二手业务的快速发展,订单系统的基础性能问题也愈发严重,作为系统运转的基石,订单库压力不容小觑。面临的问题:
迫于上述所说的DB压力问题,起初我们做了一些缓解措施,其中包括:
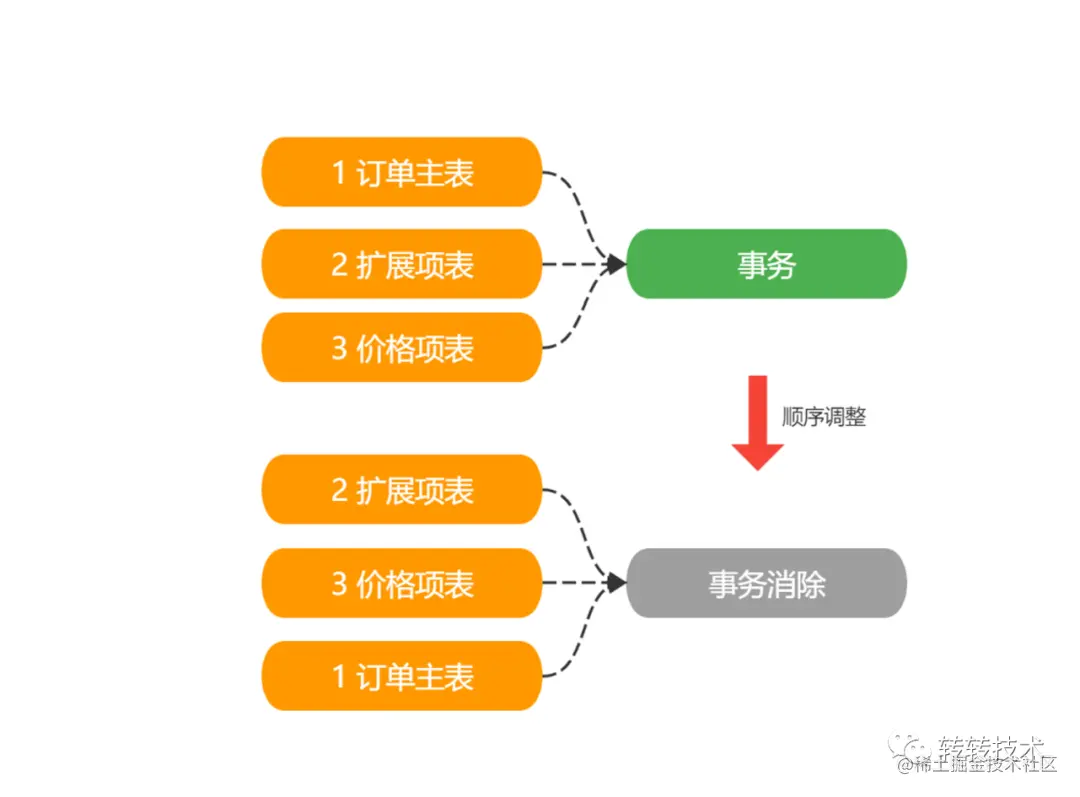
通过调整原有业务逻辑顺序将核心的生单步骤放置在最后 ,仅在订单主表保持事务,主表操作异常时其他订单相关的表允许有脏数据产生。
订单数据添加缓存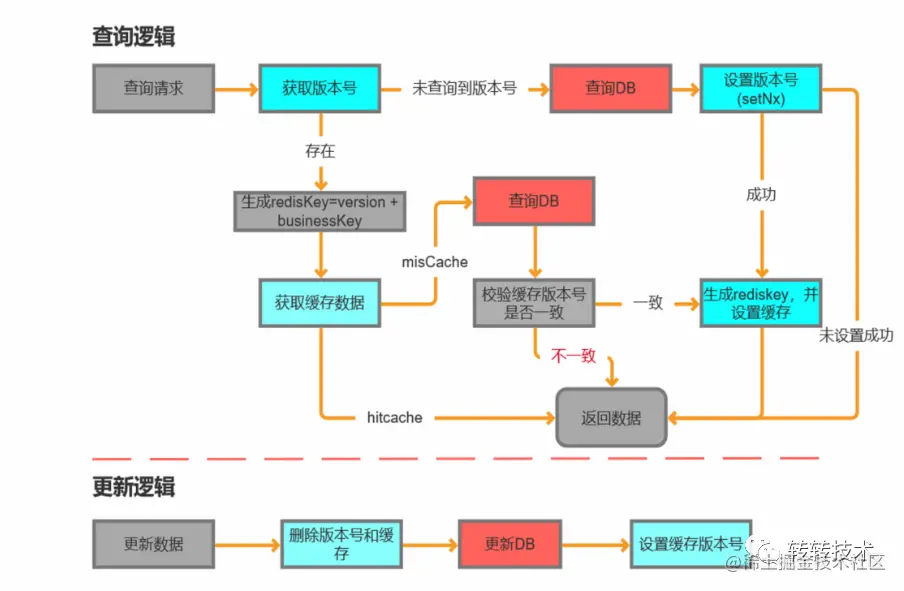
缓存这块最重要同时最麻烦的地方是保证数据的一致性,订单信息涉及结算抽佣等,数据的不实时或不一致会造成严重事故。
严格保证缓存数据的一致性,代码实现比较复杂同时会降低系统的并发,因此缓存方案实现这块我们做了一定的妥协:
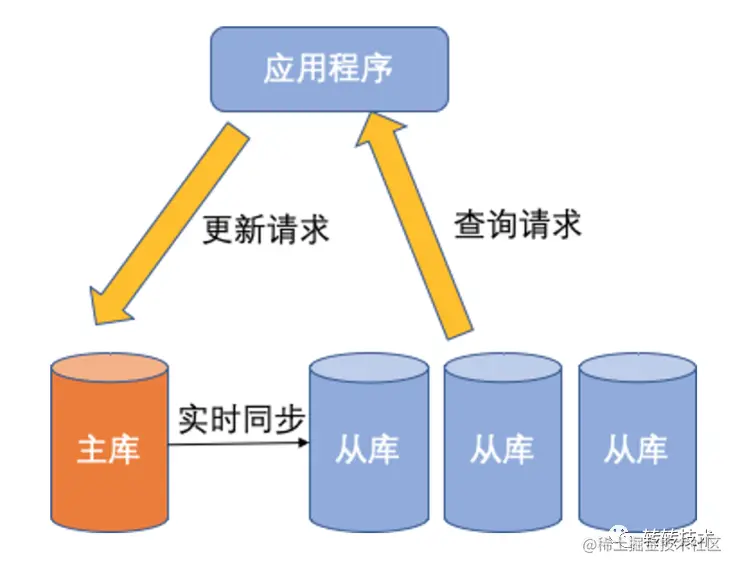
通过上述几个方面的优化DB压力虽有所下降,但面对大促等一些高并发场景时仍显得力不从心。为了从根本上解决订单库的性能问题,我们决定对订单库进行数据分片(分库分表)改造,使得未来3-5年内不需要担心订单容量问题。
数据分片组件选型这块,我们从效率、稳定性、学习成本和时间多个方面对比,最终选择了ShardingSphere。

ShardingSphere优势如下:
提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景;分片策略灵活,支持多种分片方式;集成方便、业务侵入程度低;文档丰富、社区活跃。ShardingShpere提出DB Plus的理念,采用可插拔的架构设计,模块相互独立,可以单独使用,亦可以灵活组合使用。目前ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。3款产品特性对比如下: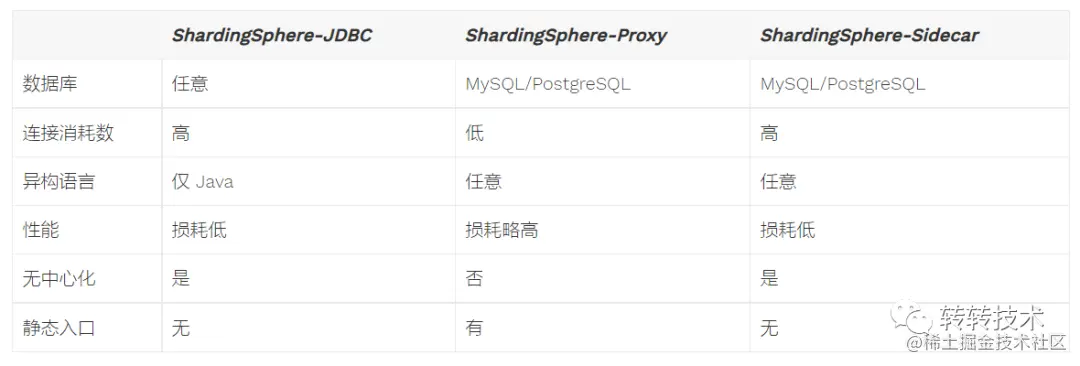
通过上图对比,结合订单高并发特性,本次数据分片中间件选择了ShardingSphere-JDBC。 ShardingSphere-JDBC定位为轻量级 Java 框架,在JDBC层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
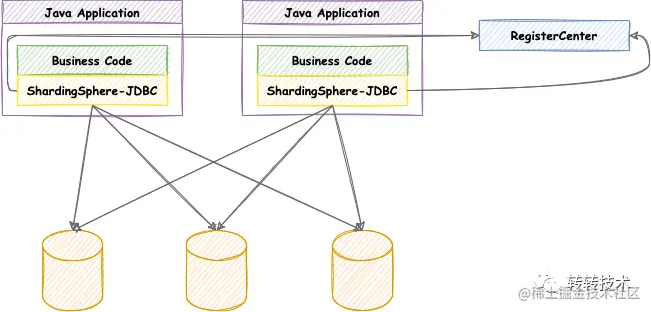
随着5.x版本的发布,ShardingSphere还提供了许多新特性:
当前订单id的生成,采用了时间戳+用户标识码+机器码+递增序列的方式,其中用户标识码取自买家id的第9~16位,该码是用户id生成时的真随机位,很适合作为分片key。
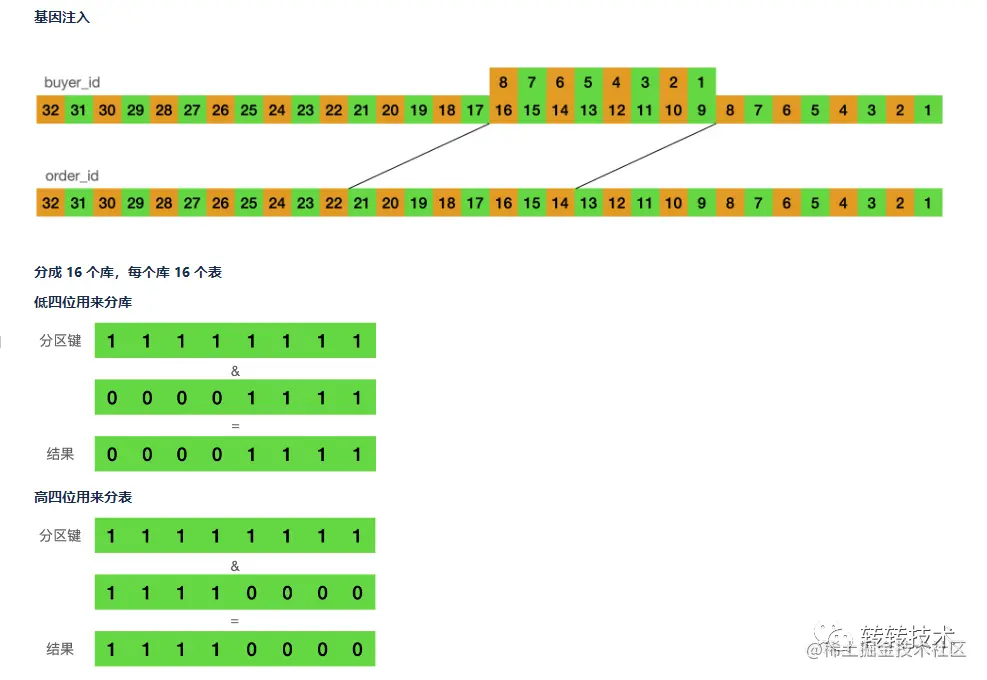
具体分片策略上:我们采用了16库16表,用户标识码取模分库,用户标识码高四位取模分表。
数据迁移步骤如下:双写->迁移历史数据->校验->老库下线。
改造前: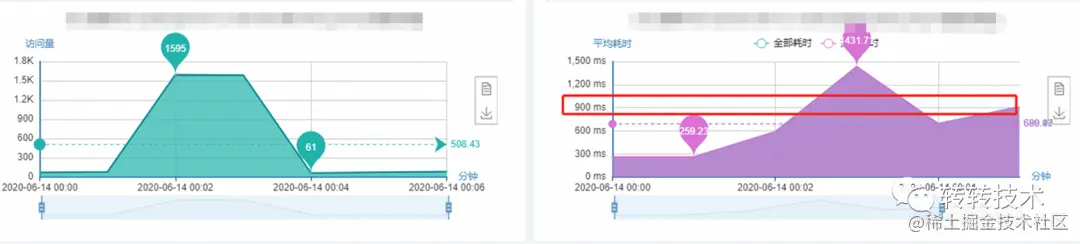
改造后: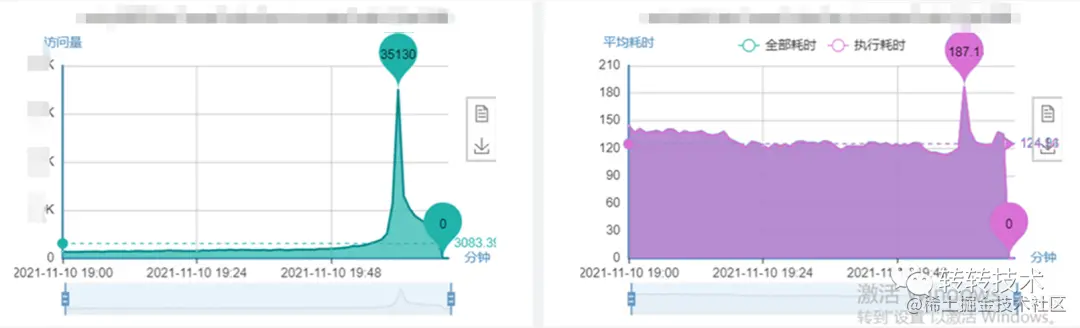
任何公司的“分库分表项目”说白了,都不是一个考验点子思路的常见项目,更多的反而是对一个人、一个团队干活的细致程度、上下游部门的沟通协作、工程化的操作实施以及抗压能力的综合考验。 同时业务的不断发展,又促使系统数据架构需要跟着不断升级,ShardingSphere以其良好的架构设计、高度灵活、可插拔和可扩展的能力简化了数据分片的开发难度,使研发团队只需关注业务本身,进而实现了数据架构的灵活扩展。
附,最终技术方案目录:



