 科技公元 后端
2023-04-12
科技公元 后端
2023-04-12
APT(Annotation Processing Tool)它是Java编译期注解处理器,它可以让开发人员在编译期对注解进行处理,通过APT可以获取到注解和被注解对象的相关信息,并根据这些信息在编译期按我们的需求生成java代码模板或者配置文件(比如SPI文件或者spring.fatories)等。APT获取注解及生成代码都是在代码编译时候完成的,相比反射在运行时处理注解大大提高了程序性能
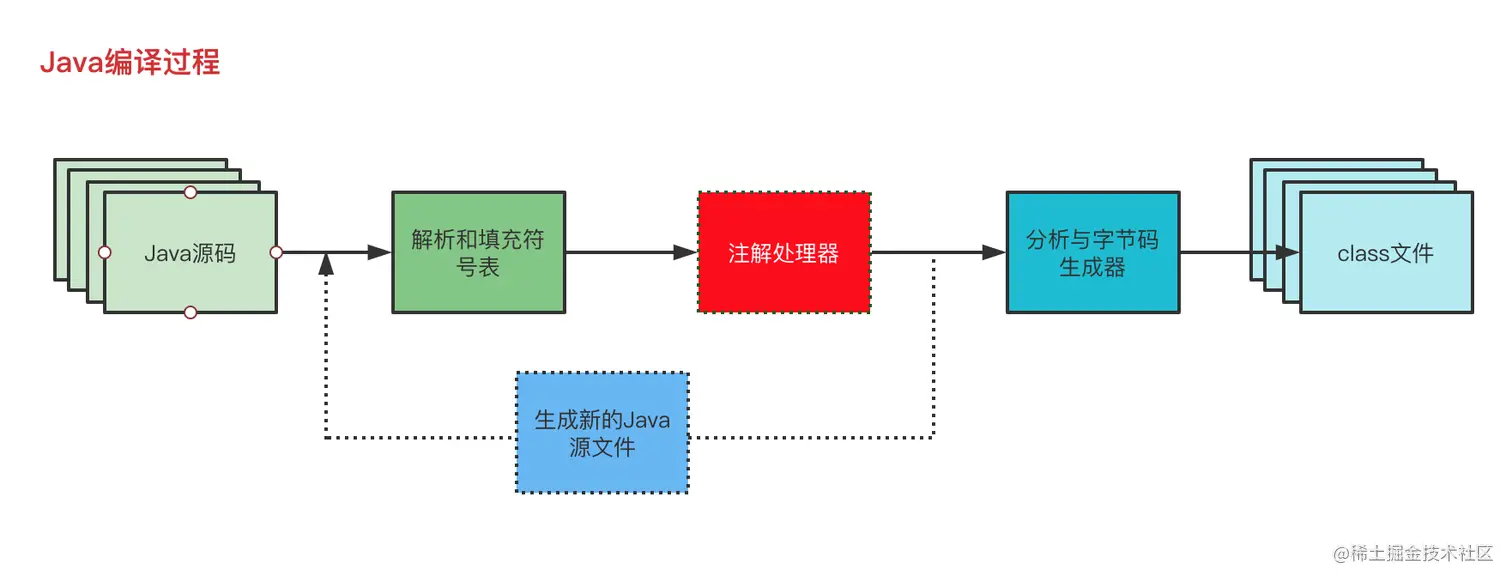
注:因为APT = 注解+ 注解处理器(AbstractProcessor)。因此需要了解什么是注解,不过对于java开发人员来说,注解应该是耳熟能详了,这边就不再论述。如果不了解啥是注解的小伙伴,可以查看如下文章科普一下
这边得特别说下元注解@Retention
 因为APT是在java编译器使用,因此@Retention的value通常指定为source或者class,这样可以提高一点性能。就我个人而言,我倾向指定为source
因为APT是在java编译器使用,因此@Retention的value通常指定为source或者class,这样可以提高一点性能。就我个人而言,我倾向指定为source
1、常用元素
 这些元素映射到java,我通过一个例子大家应该就可以了解这些元素是指什么
这些元素映射到java,我通过一个例子大家应该就可以了解这些元素是指什么

2、Element元素常用变量
 更多element详细内容可以查看如下链接
更多element详细内容可以查看如下链接
注: 示例要实现的功能,通过一个自定义注解AutoComponent,通过注解处理器扫描解析AutoComponent注解,并生成lybgeek.components,spring通过解析lybgeek.components,实现bean注册
1、创建注解类
@Documented
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.TYPE)
public @interface AutoComponent {
}
复制代码2、创建一个继承自 AbstractProcessor 的类
这边需介绍这个类里面几个核心的方法
public synchronized void init(ProcessingEnvironment processingEnv)
复制代码init方法可以让我们处理器的初始化阶段,通过ProcessingEnvironment来获取一些帮助我们来处理注解的工具类
// Element操作类,用来处理Element的工具
Elements elementUtils = processingEnv.getElementUtils();
// 类信息工具类,用来处理TypeMirror的工具
Types typeUtils = processingEnv.getTypeUtils();
// 日志工具类,因为在process()中不能抛出一个异常,那会使运行注解处理器的JVM崩溃。所以Messager提供给注解处理器一个报告错误、警告以及提示信息的途径,用来写一些信息给使用此注解器的第三方开发者看
Messager messager = processingEnv.getMessager();
// 文件工具类,常用来读取或者写资源文件
Filer filer = environment.getFiler();
复制代码public Set<String> getSupportedAnnotationTypes()
复制代码getSupportedAnnotationTypes方法用来指定需要处理的注解集合,返回的集合元素需要是注解全路径(包名+类名)
public SourceVersion getSupportedSourceVersion()
复制代码getSupportedSourceVersion方法用来指定当前正在使用的Java版本,一般返回SourceVersion.latestSupported()表示最新的java版本即可
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv)
复制代码process是注解处理器核心方法,注解的处理和生成代码或者配置资源都是在这个方法中完成。
Java官方文档给出的注解处理过程的定义:注解处理过程是一个有序的循环过程。在每次循环中,一个处理器可能被要求去处理那些在上一次循环中产生的源文件和类文件中的注解。
每次循环都会调用process方法,process方法提供了两个参数,第一个是我们请求处理注解类型的集合(也就是我们通过重写getSupportedAnnotationTypes方法所指定的注解类型),第二个是有关当前和上一次循环的信息的环境。返回值表示这些注解是否由此 Processor 声明,如果返回 true,则这些注解已声明并且不要求后续 Processor 处理它们;如果返回 false,则这些注解未声明并且可能要求后续 Processor 处理它们。
核心方法介绍完后,我们通过示例来自定义一个注解处理器
@AutoService(Processor.class)
@SupportedOptions("debug")
public class AutoComponentProcessor extends AbstractComponentProcessor {
/**
* 元素辅助类
*/
private Elements elementUtils;
private Set<String> componentClassNames = new ConcurrentSkipListSet<>();
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
elementUtils = processingEnv.getElementUtils();
}
@Override
public Set<String> getSupportedAnnotationTypes() {
return Collections.singleton(AutoComponent.class.getName());
}
@Override
protected boolean processImpl(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
// 注解处理完成,创建配置文件
if (roundEnv.processingOver()) {
generateConfigFiles();
} else {
processAnnotations(annotations, roundEnv);
}
return false;
}
复制代码3、注册处理器
因为处理器是通过SPI机制实现,因此它的注册,其实就是在META-INF/services底下创建javax.annotation.processing.Processor文件,文件内容为自定义的处理器类
com.github.lybgeek.apt.process.AutoComponentProcessor
复制代码不过我们可以在项目的POM中引入GAV
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.0.1</version>
<scope>provided</scope>
</dependency>
复制代码或者
<dependency>
<groupId>net.dreamlu</groupId>
<artifactId>mica-auto</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
复制代码在process的处理器上,加上注解
@AutoService(Processor.class)
复制代码就会在编译期自动生成spi配置文件,它实现机制也是采用APT
4、当我们制作好处理器后,我们可以将处理器打成jar,提供给项目用
示例
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>springboot-apt-framework</artifactId>
<version>${project.version}</version>
</dependency>
复制代码在项目编译后,就会在target的MATA-INF底下看到lybgeek.components文件
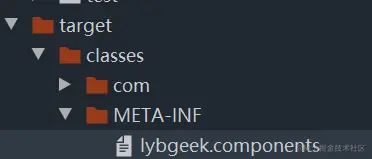 文件内容如下
文件内容如下
# Generated by LYB-GEEK AT TIME : 2023-01-12T17:14:24.982
com.github.lybgeek.test.service.EchoService
com.github.lybgeek.test.service.HelloService
复制代码接下来就是解析lybgeek.components,并通过spring提供的扩展点和API进行bean注册,因为这块内容不属于APT的内容,本文就不再论述,对这部分感兴趣的朋友,可以通过文末提供的demo链接查看
在未接触APT之前,我们可能会通过反射去解析注解并实现功能,接触APT之后,我们又多了额外一种比反射更能提升性能的实现实现。不过任何东西都有其适用场景,APT主要还是用在编译期帮我们生成代码或者配置等,如果我们项目要使用APT生成的代码,有可能还是需要通过反射处理。
我们耳熟能详的lombok、mapstruct、包括spring5.0之后提供的@Index都是通过APT来实现,文中的示例其实就是仿造spring index来实现,可以看成是spring index的简单版本


