集成学习
集成学习正是使用多个个体学习器来获得比每个单独学习器更好的预测性能。
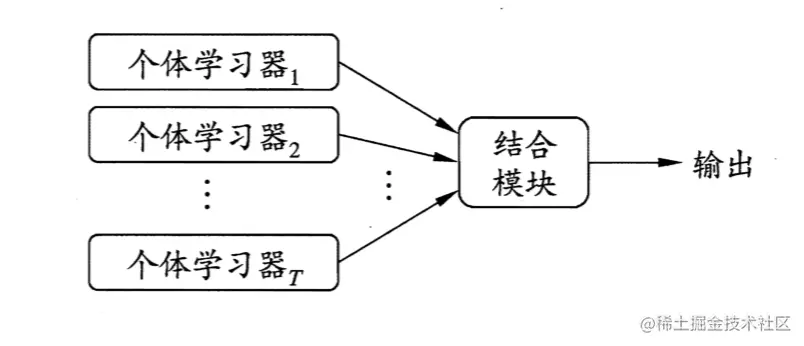
性能优劣不一的个体学习器放在一块儿可能产生的是更加中庸的效果,即比最差的要好,也比最好的要差。那么集成学习如何实现“1 + 1 > 2”呢?这其实是对个体学习器提出了一些要求。
- 一方面,个体学习器的性能要有一定的保证。如果每个个体学习器的分类精度都不高,在集成时错误的分类结果就可能占据多数,导致集成学习的效果甚至会劣于原始的个体学习器。
- 另一方面,个体学习器的性能要有一定的差异,和而不同才能取得进步。多样性(diversity)是不同的个体学习器性能互补的前提。
由于个体学习器是为了解决相同问题训练出来的,要让它们的性能完全独立着实是勉为其难。尤其是当个体学习器的准确性较高时,要获得多样性就不得不以牺牲准确性作为代价。由此,集成学习的核心问题在于在多样性和准确性间做出折中,进而产生并结合各具优势的个体学习器。
个体学习器的生成方式很大程度上取决于数据的使用策略。根据训练数据使用方法的不同,集成学习方法可以分为两类:个体学习器间存在强依赖关系因而必须串行生成的序列化方法,和个体学习器之间不存在强依赖关系因而可以同时生成的并行化方法。
- 典型的序列化学习算法是自适应提升方法(Adaptive Boosting),人送绰号 AdaBoost。在解决分类问题时,提升方法遵循的是循序渐进的原则。先通过改变训练数据的权重分布,训练出一系列具有粗糙规则的弱个体分类器,再基于这些弱分类器进行反复学习和组合,构造出具有精细规则的强分类器。从以上的思想中不难看出,AdaBoost 要解决两个主要问题:训练数据权重调整的策略和弱分类器结果的组合策略。
- 典型的并行化学习方法是随机森林方法。正所谓“独木不成林”,随机森林就是对多个决策树模型的集成。“随机”的含义体现在两方面:一是每个数据子集中的样本是在原始的训练数据集中随机抽取的;二是在决策树生成的过程中引入了随机的属性选择。在随机森林中,每棵决策树在选择划分属性时,首先从结点的属性集合中随机抽取出包含 k 个属性的一个子集,再在这个子集中选择最优的划分属性生成决策树。
聚类分析
聚类分析是一种无监督学习方法,其目标是学习没有分类标记的训练样本,以揭示数据的内在性质和规律。具体来说,聚类分析要将数据集划分为若干个互不相交的子集,每个子集中的元素在某种度量之下都与本子集内的元素具有更高的相似度。
分类和聚类的区别于此:分类是先确定类别再划分数据;聚类则是先划分数据再确定类别。
聚类分析这项任务的两个核心问题:一是如何判定哪些样本属于同一“类”,二是怎么让同一类的样本“聚”在一起。
解决哪些样本属于同一“类”的问题需要对相似性进行度量。无论采用何种划定标准,聚类分析的原则都是让类内样本之间的差别尽可能小,而类间样本之间的差别尽可能大。度量相似性最简单的方法就是引入距离测度,聚类分析正是通过计算样本之间的距离来判定它们是否属于同一个“类”。
确定了“类”的标准之后,接下来就要考虑如何让同一类的样本“聚”起来,也就是聚类算法的设计。最主要的聚类算法如下:
- 层次聚类又被称为基于连接的聚类,其核心思想源于样本应当与附近而非远离的样本具有更强的相关性。由于聚类生成的依据是样本之间的距离,因而聚类的特性可以用聚类内部样本之间的距离尺度来刻画。聚类的划分是在不同的距离水平上完成的,划分过程就可以用树状图来描述,这也解释了 " 层次聚类 " 这个名称的来源。
- 原型聚类又被称为基于质心的聚类,其核心思想是每个聚类都可以用一个质心表示。原型聚类将给定的数据集初始分裂为若干聚类,每个聚类都用一个中心向量来刻画,然后通过反复迭代来调整聚类中心和聚类成员,直到每个聚类不再变化为止。
- 分布聚类又被称为基于概率模型的聚类,其核心思想是假定隐藏的类别是数据空间上的一个分布。在分布聚类中,每个聚类都是最可能属于同一分布的对象的集合。这种聚类方式类似于数理统计中获得样本的方式,也就是每个聚类都由在总体中随机抽取独立同分布的样本组成。其缺点则在于无法确定隐含的概率模型是否真的存在,因而常常导致过拟合的发生。
- 密度聚类又被称为基于密度的聚类,其核心思想是样本分布的密度能够决定聚类结构。每个样本集中分布的区域都可以看作一个聚类,聚类之间由分散的噪声点区分。密度聚类算法根据样本密度考察样本间的可连接性,再基于可连接样本不断扩展聚类以获得最终结果。
降维学习
根据凡事抓主要矛盾的原则,对举足轻重的属性要给予足够的重视,无关紧要的属性则可以忽略不计,这在机器学习中就体现为降维的操作。
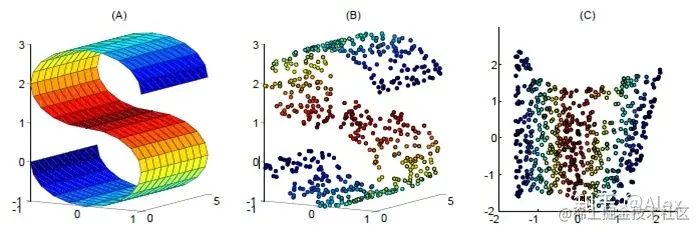
主成分分析是一种主要的降维方法,它利用正交变换将一组可能存在相关性的变量转换成一组线性无关的变量,这些线性无关的变量就是主成分。
主成分分析遵循如下的步骤:
- 数据规范化:对 m 个样本的相同属性值求出算术平均数,再用原始数据减去平均数,得到规范化后的数据;
- 协方差矩阵计算:对规范化后的新样本计算不同属性之间的协方差矩阵,如果每个样本有 n 个属性,得到的协方差矩阵就是 n 维方阵;
- 特征值分解:求解协方差矩阵的特征值和特征向量,并将特征向量归一化为单位向量;
- 降维处理:将特征值按照降序排序,保留其中最大的 k 个,再将其对应的 k 个特征向量分别作为列向量组成特征向量矩阵;
- 数据投影:将减去均值后的 m×n 维数据矩阵和由 k 个特征向量组成的 n×k 维特征向量矩阵相乘,得到的 m×k 维矩阵就是原始数据的投影。
主成分分析中降维的实现并不是简单地在原始特征中选择一些保留,而是利用原始特征之间的相关性重新构造出新的特征。
为什么简单的数学运算能够带来良好的效果呢?
从线性空间的角度理解,主成分分析可以看成将正交空间中的样本点以最小误差映射到一个超平面上。如果这样的超平面存在,那它应该具备以下的性质:一方面,不同样本点在这个超平面上的投影要尽可能地分散;另一方面,所有样本点到这个超平面的距离都应该尽可能小。



